




When you first think about converting a list of tensors to a single tensor, it seems easy, but it is slightly complicated depending on how you want to merge those tensors. It requires considering multiple scenarios.
Here are six scenarios that cover the whole topic:
Scenario 1: List of tensors with the same shape and type
What if you have a list of tensors, and each tensor contains the same shape and data type? Your work becomes very easy in that scenario because you don’t need any extra operations.
For merging all the list tensors into a single tensor, you have two options:
torch.stack()

The above figure describes the step-by-step guide. First, convert the individual tensors into a list and then pass that list to the .stack() method to transform it into a single tensor.
If you want to stack all the tensors into a single tensor and create a new dimension, you should use torch.stack() method. For example, if you have a list of 1D tensors, if you stack them using the .stack() method, it will become a 2D tensor.
import torch tensor1 = torch.tensor([100, 101, 102]) tensor2 = torch.tensor([201, 202, 204]) tensor_list = [tensor1, tensor2] stacked_tensor = torch.stack(tensor_list) print(stacked_tensor) # Output: # tensor([[100, 101, 102], # [201, 202, 204]]) print(stacked_tensor.shape) # Output: torch.Size([2, 3])
The output tensor’s size is [2, 3], which means it is now a 2D tensor, but a single tensor.
torch.cat()

What if you don’t want to create a new dimension and concatenate along an existing dimension? In that case, you should use torch.cat() method. For example, if you have a list of 1D tensors, the output tensor also has a 1D with elements of each tensor of the list.
import torch tensor1 = torch.tensor([100, 101, 102]) tensor2 = torch.tensor([201, 202, 204]) tensor_list = [tensor1, tensor2] concatenated_tensor = torch.cat(tensor_list) print(concatenated_tensor) # Output: tensor([100, 101, 102, 201, 202, 204]) print(concatenated_tensor.shape) # Output: torch.Size([6])
The output is a single 1D tensor from a list of 1D tensors.
If you want to extend a dimension, use the .stack() method. If you will merge all the tensors into a single tensor along an existing dimension, use the .cat() method. This is the main difference between these two methods.
Ensure that each tensor has the same shape. Otherwise, it will throw a RuntimeError.
Scenario 2: List of tensors with different shapes
In a real-life project, this is the likely scenario you will come across. Most of the tensors in your list will have different shapes.
Let’s say we have three tensors, and all three have different shapes. Now, let’s try to combine them into one tensor and see the output:
import torch tensor1 = torch.tensor([100]) tensor2 = torch.tensor([201, 202]) tensor3 = torch.tensor([301, 302, 303]) tensor_list = [tensor1, tensor2, tensor3] stacking_tensors = torch.stack(tensor_list) print(stacking_tensors) # Output: RuntimeError: stack expects each tensor to be equal size, # but got [1] at entry 0 and [2] at entry 1
And we get the RuntimeError: stack expects each tensor to be equal size, but got [1] at entry 0 and [2] at entry 1. Why? Because the shapes of each tensor are different.
To apply the .stack() or .cat() method, we need to ensure that each tensor has the same shape.
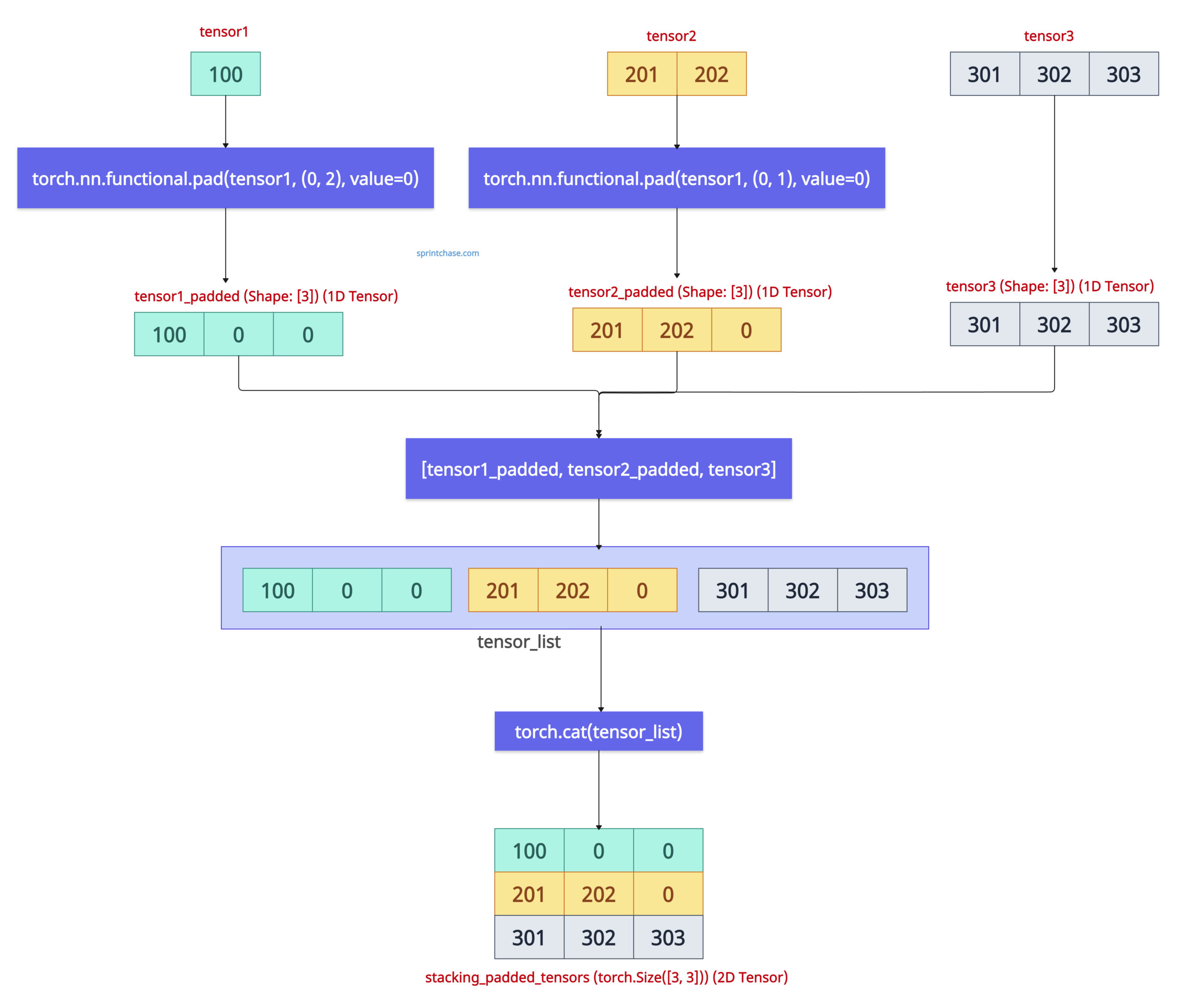
To fix the RuntimeError, we must pad the tensors with 0 using torch.nn.functional.pad() function. After the padding, each tensor will have the same shape, and we can apply the .stack() or .cat() function easily.
import torch import torch.nn.functional as F tensor1 = torch.tensor([100]) tensor2 = torch.tensor([201, 202]) tensor3 = torch.tensor([301, 302, 303]) tensor1_padded = F.pad(tensor1, (0, 2), value=0) tensor2_padded = F.pad(tensor2, (0, 1), value=0) tensor_list = [tensor1_padded, tensor2_padded, tensor3] stacking_padded_tensors = torch.stack(tensor_list) print(stacking_padded_tensors) # Output: # tensor([[100, 0, 0], # [201, 202, 0], # [301, 302, 303]]) print(stacking_padded_tensors.shape) # Output: torch.Size([3, 3])
In the first tensor of the list, we padded two 0s to create three elements in the second tensor; we padded 1 zero to create three elements, and the third tensor already has three elements.
The final stacked_padded_tensor is two-dimensional with zero values, resulting from padding.
Scenario 3: List of tensors with different data types
What if your list contains different types of tensors? For example, it can have float32 and int64 types. How will you combine them into one?
In this case, we need to convert all the tensors into a common data type using the tensor.to(dtype) method.
import torch tensor1 = torch.tensor([101., 102., 103.]) print(tensor1.dtype) # Output: torch.float32 tensor2 = torch.tensor([201, 202, 204]) print(tensor2.dtype) # Output: torch.int64 tensor_list_different_types = [tensor1, tensor2] tensor_list = [t.to(dtype=torch.float32) for t in tensor_list_different_types] stacked_same_dtype_tensors = torch.stack(tensor_list) print(stacked_same_dtype_tensors) # Output: # tensor([[101., 102., 103.], # [201., 202., 204.]]) print(stacked_same_dtype_tensors.shape) # Output: torch.Size([2, 3])
Our first tensor is of type float32, and the second is of type int64.
Using the .to() method, we converted each tensor’s type into float32 and stacked them into one tensor.
If you are working with neural networks, it is a good idea to convert all of your tensors’ type to float32.
If working with indices, you should convert your tensors into int64 types.
Scenario 4: Nested List of Tensors (Multilevel Batching)
What if you have a nested list of tensors? This means you have a list of lists that contain tensors. In that case, we need a recursive stacking or nested torch.stack() function calls.
import torch nested_t1 = torch.tensor([[1, 2], [3, 4]]) nested_t2 = torch.tensor([[5, 6], [7, 8]]) tensor_list = [nested_t1, nested_t2] single_tensor = torch.stack(tensor_list) print(single_tensor) # Output: # tensor([[[1, 2], # [3, 4]], # [[5, 6], # [7, 8]]]) print(single_tensor.shape) # Output: torch.Size([2, 2, 2])
Scenario 5: List of Tensors on Different Devices
If your tensors are on different devices, like some on CPU and some on GPU, first you need to move all the tensors to one device and then convert them into a single tensor.
To move tensors in PyTorch, you can use the tensor.to(device) method. Here, the device can be a “cpu” or “cuda:0”.
import torch
# List of tensors on different devices
tensor_list = [torch.randn(2, 3).cuda(), torch.randn(2, 3).cpu()]
# Move all tensors to the same device (e.g., GPU if available)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
tensor_list = [t.to(device) for t in tensor_list]
# Stack tensors
stacked_tensor = torch.stack(tensor_list, dim=0)
print(stacked_tensor)
print("Stacked tensor device:", stacked_tensor.device)

Before moving the tensors to the GPU, we check if the GPU is available in PyTorch.
The above output screenshot shows that we have a GPU available.
As a result, we moved all the tensors to the GPU device and then stacked the list of tensors, resulting in a single tensor.
Scenario 6: List contains scalar tensors
What if our list contains scalar tensors? A scalar tensor means it is a 0D tensor.
You can have a single tensor from a list of scalars without creating a new dimension using torch.tensor() method. When working with scalars, we must avoid torch.stack() method because they’re 0D and don’t behave like arrays.
import torch scalar_tensor1 = torch.tensor(19.0) scalar_tensor2 = torch.tensor(21.0) scalar_list = [scalar_tensor1, scalar_tensor2] single_tensor = torch.tensor([x.item() for x in scalar_list]) print(single_tensor) # Output: tensor([19., 21.]) print(single_tensor.shape) # Output: torch.Size([2])
Without using .stack() or .cat(), we now have a 1D tensor from a list of 0D tensors.
That’s all!