



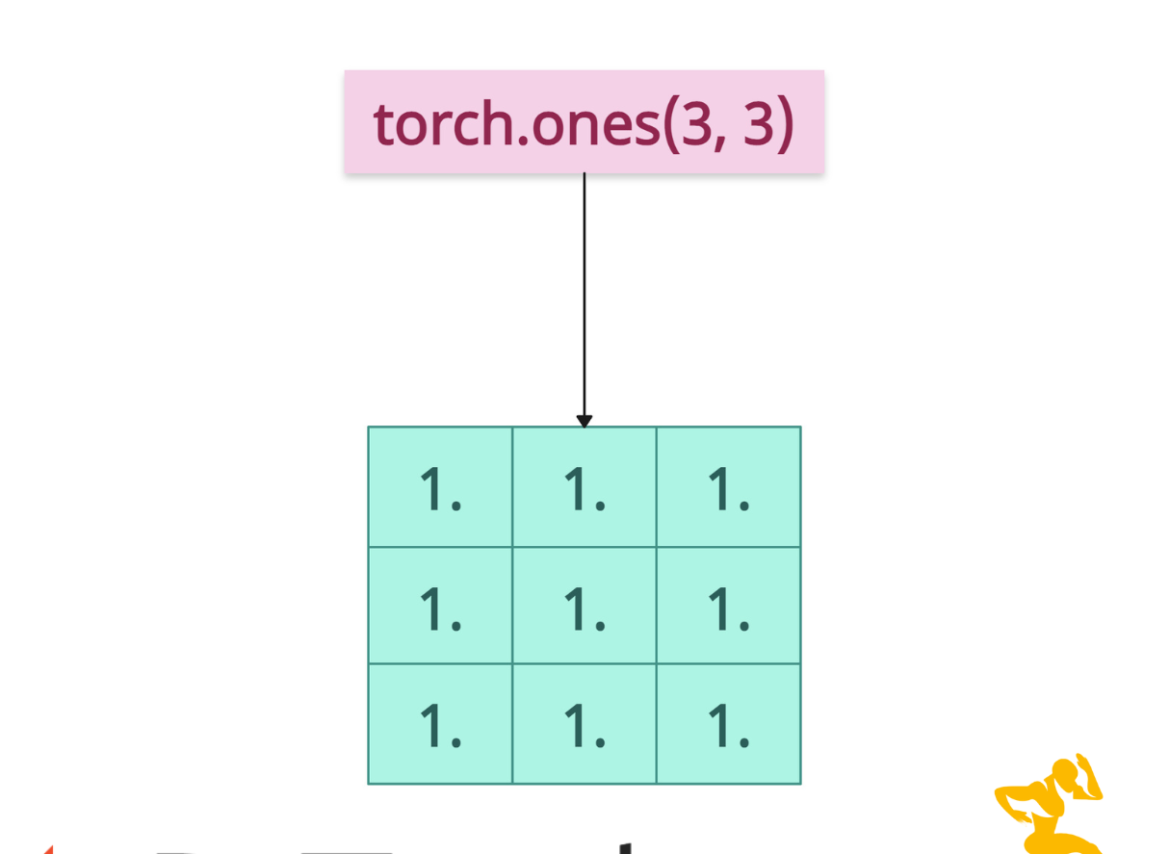
torch.ones()
The torch.ones() method in PyTorch generates a tensor filled with the scalar value 1, with the specified shape, data type, device, and other optional parameters.
 The primary purpose of this method is to create masks, biases, or initialize weights in neural networks. You can use it to create 1D or multidimensional tensors.
The primary purpose of this method is to create masks, biases, or initialize weights in neural networks. You can use it to create 1D or multidimensional tensors.
Syntax
torch.ones(*size,
out=None,
dtype=None,
layout=torch.strided,
device=None,
requires_grad=False)
Parameters
| Arguments | Description |
| *size (int) | It defines the shape of the output tensor. For example, (2, 3) means a 2×3 tensor. |
| out (Tensor, optional) | If you have already pre-allocated a tensor, you can use the “out” argument to store the result in this pre-allocated tensor. |
| dtype (torch.dtype, optional) | By default, the data type is torch.float32, but using the dtype argument, you can set it to any acceptable data type. For example, torch.float63, torch.int64, torch.int32, etc. |
| layout (torch.layout, optional) | It determines the layout of the tensor. By default, it is torch.strided. |
| device (torch.device, optional) | It defines the current device. It can be either “CPU” or “CUDA”. |
| requires_grad (bool, optional) | It is a Boolean argument that defines whether an output tensor requires gradient computation. By default, it is False, but if True, it tracks gradients for autograd. |
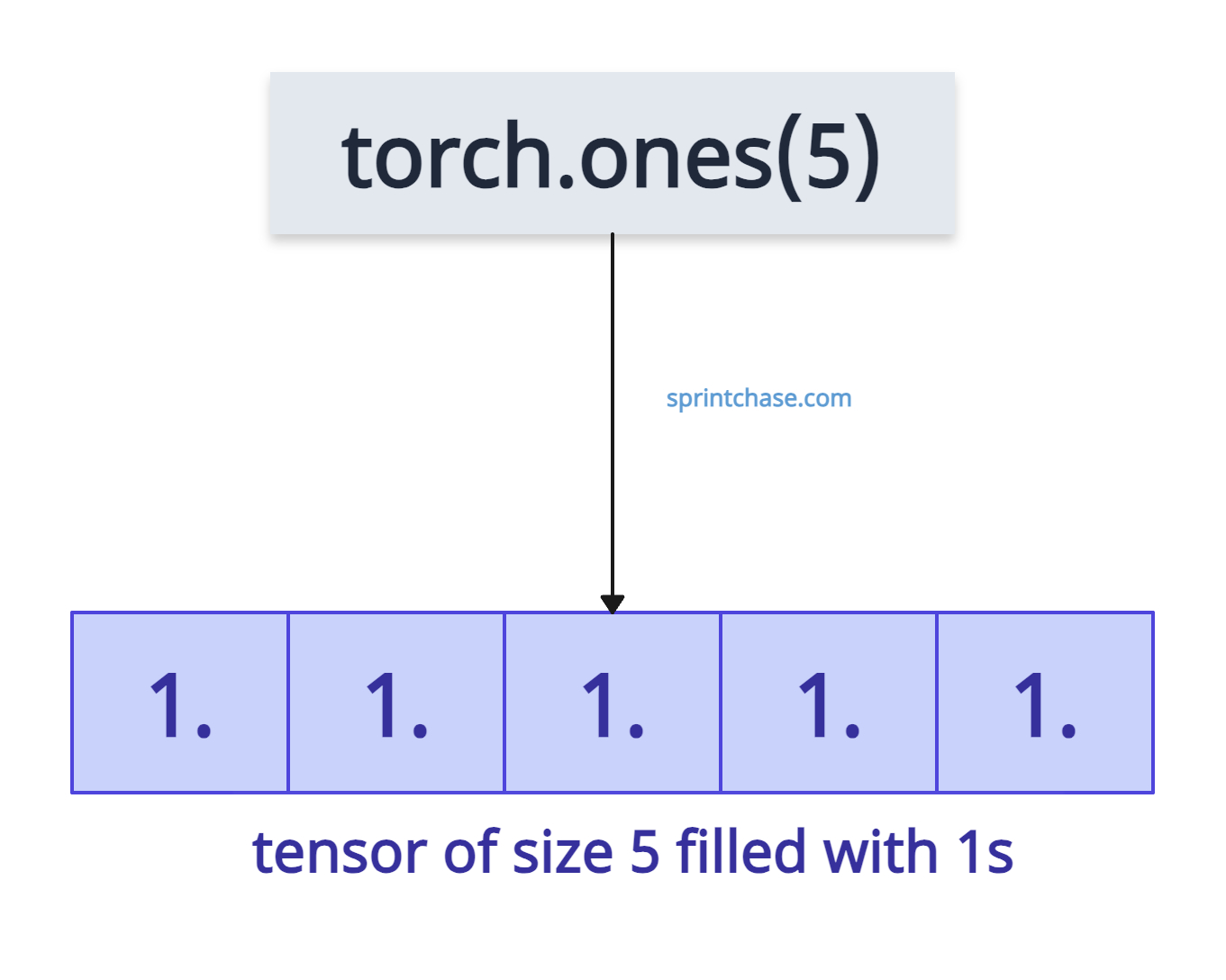
Creating a Simple 1D Tensor
Let’s initialize a 1D tensor of ones.
import torch tensor = torch.ones(5) print(tensor) # Output: tensor([1., 1., 1., 1., 1.])We can check the shape of the above-generated tensor using the .shape attribute.
import torch tensor = torch.ones(5) print(tensor.shape) # Output: torch.Size([5])
You can see that the shape is one-dimensional.
Generating a multidimensional tensor
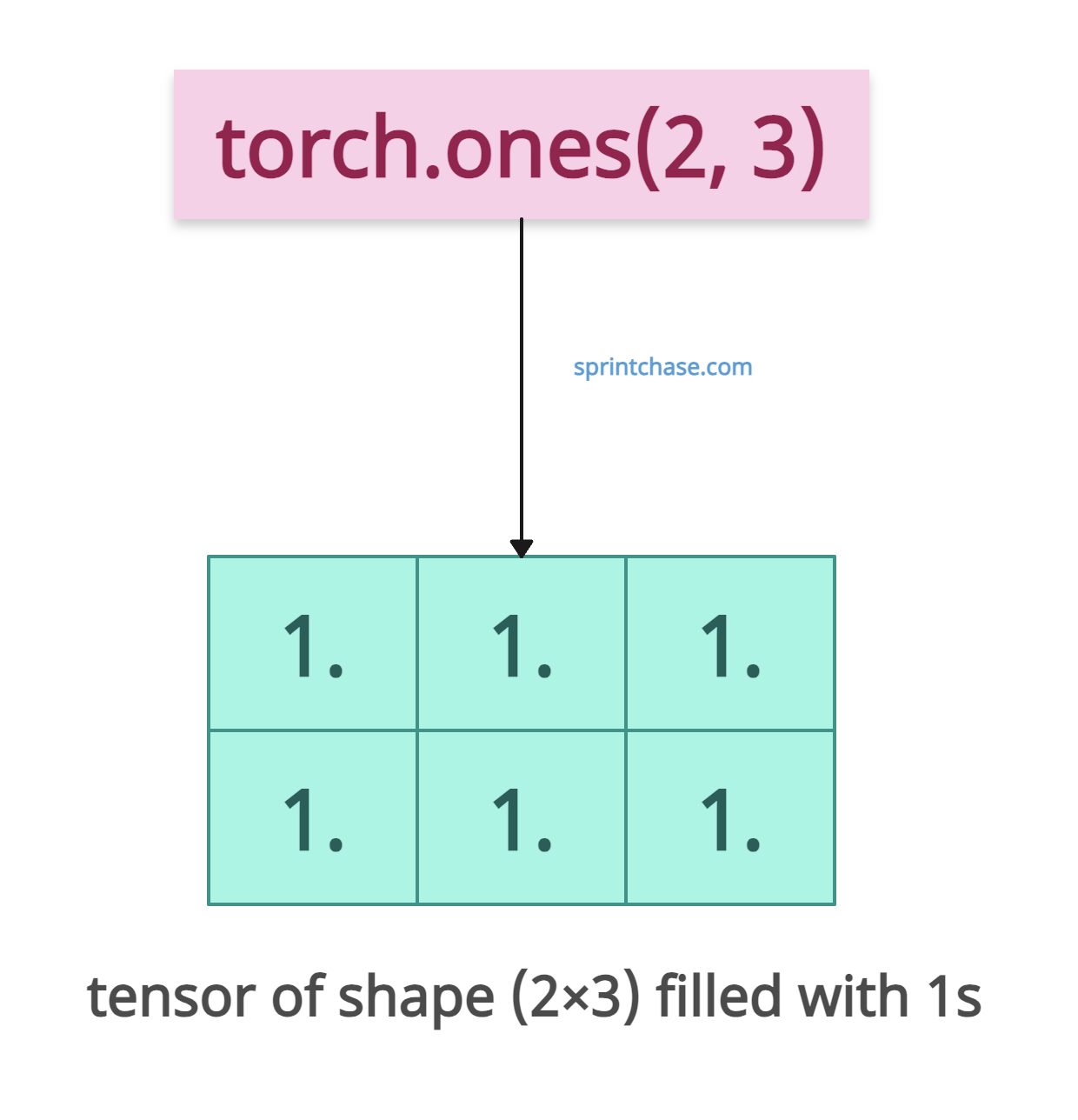
We need multidimensional tensors for matrix operations or neural network layers. For that usage, we can initialize a multidimensional tensor with 1s.
import torch tensor = torch.ones(2, 3) print(tensor) # Output: tensor([[1., 1., 1.], # [1., 1., 1.]])
Creating 1s on GPU
By passing a “device” argument to value “cuda”, we can create a tensor on the GPU. However, ensure that you are using a GPU. If you are on CPU, it will throw an error.
I have already written a guide on how to check if you are connected to the GPU.
import torch
if torch.cuda.is_available():
tensor = torch.ones(2, 2, device='cuda')
print(tensor)
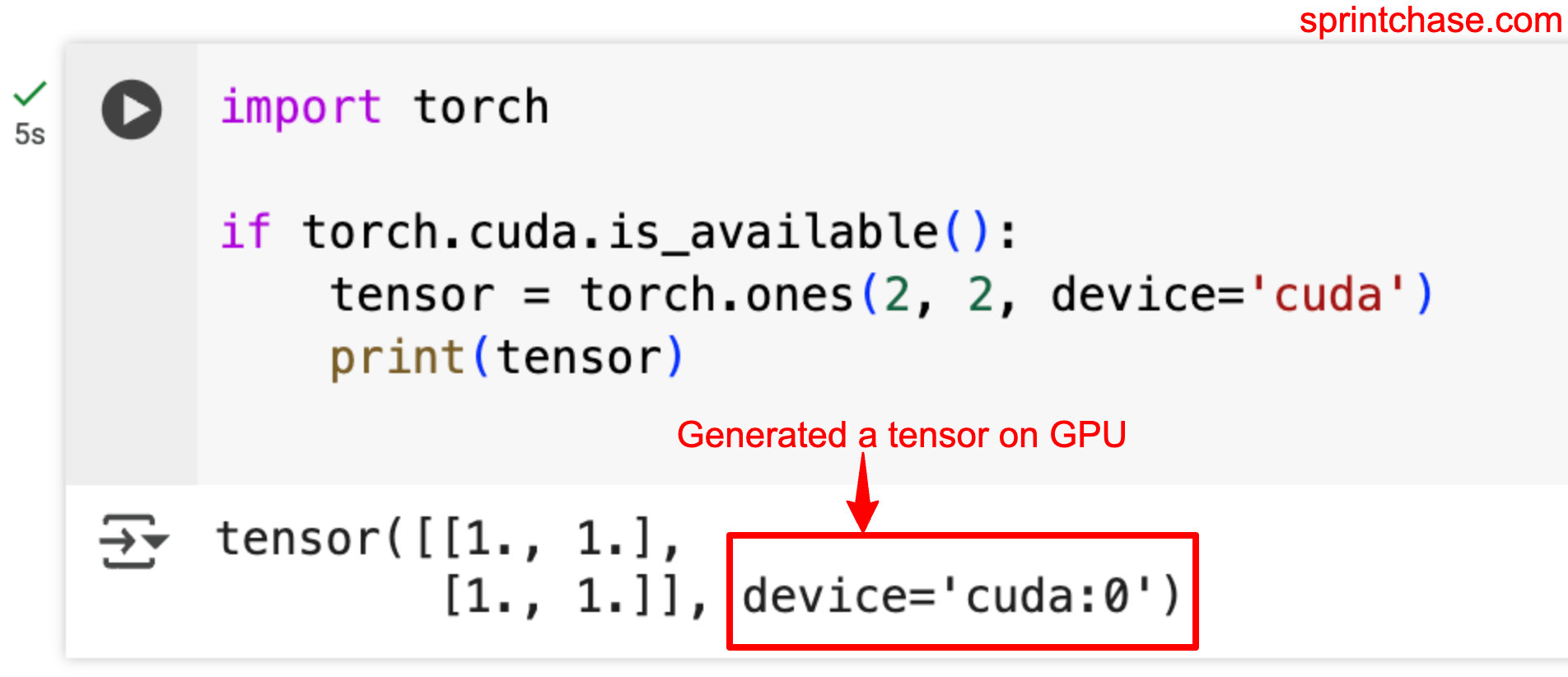
The screenshot above proves we generated a 2D tensor filled with 1s on a GPU device.
Specifying Data Type
Let’s generate an integer tensor by passing dtype=”torch.int64″.import torch int_tensor = torch.ones(2, 2, dtype=torch.int64) print(int_tensor) # Output: tensor([[1, 1], # [1, 1]])
Gradient tracking
We can enable gradient computation to train neural networks by passing require_grad=True.
import torch grad_tensor = torch.ones((3, 3), requires_grad=True) print(grad_tensor) # Output: # tensor([[1., 1., 1.], # [1., 1., 1.], # [1., 1., 1.]], requires_grad=True)
Pre-allocation
To pre-allocate a tensor, we can use torch.empty() or torch.zeros() function. It can be used to initialize a tensor, and then you can fill it with the result for further processing.
import torch pre_allocated_tensor = torch.empty(4, 4) torch.ones(4, 4, out=pre_allocated_tensor) print(pre_allocated_tensor) # Output: # tensor([[1., 1., 1., 1.], # [1., 1., 1., 1.], # [1., 1., 1., 1.], # [1., 1., 1., 1.]])
torch.ones_like()
The torch.ones_like() method creates a tensor filled with the scalar value 1, with the same size, shape, and data type as the input tensor.
Syntax
torch.ones_like(input,
dtype=None,
layout=None,
device=None,
requires_grad=False,
memory_format=torch.preserve_format)
Parameters
| Arguments | Description |
| input (Tensor) | It represents a reference tensor that will determine the size of the output tensor. |
| dtype (torch.dtype, optional) | It is the desired data type of the output tensor. By default, it is a type of input tensor. |
| layout (torch.layout, optional) | It determines the layout of the tensor. By default, it is torch.strided. |
| device (torch.device, optional) | It defines the current device. It can be either “CPU” or “CUDA”. |
| requires_grad (bool, optional) | It is a Boolean argument that defines whether an output tensor requires gradient computation. By default, it is False, but if True, it tracks gradients for autograd. |
| memory_format (optional) |
It is the memory format of the output tensor. The default value is torch.preserve_format. |
Basic usage
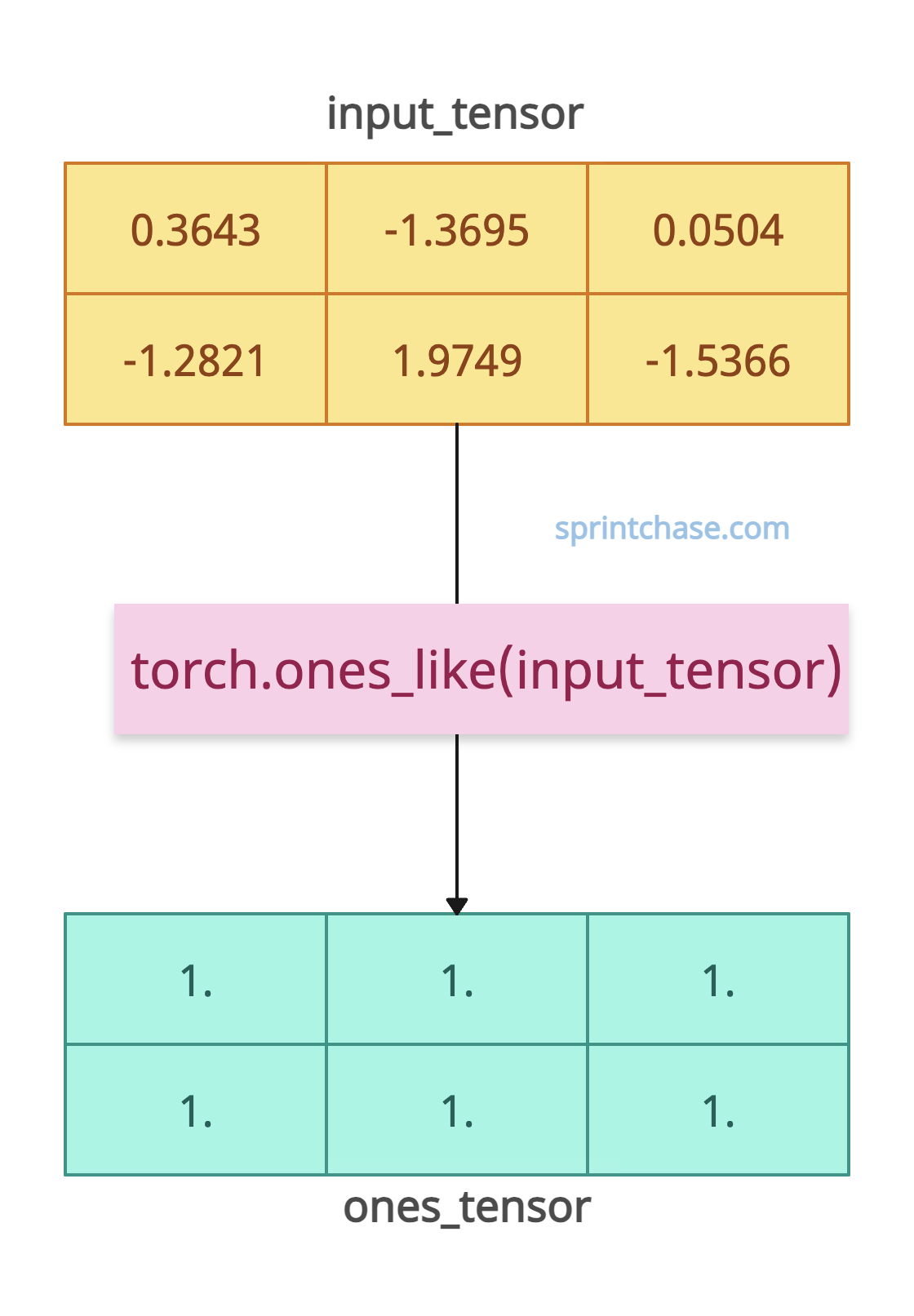
Let’s define a 2×3 tensor using torch.randn() method and create a tensor of the same shape and size with scalar 1s.
import torch
input_tensor = torch.randn(2, 3)
ones_tensor = torch.ones_like(input_tensor)
print("Input Tensor:\n", input_tensor)
# Input Tensor:
# tensor([[ 0.3643, -1.3695, 0.0504],
# [-1.2821, 1.9749, -1.5366]])
print("Output Tensor:\n", ones_tensor)
# Output Tensor:
# tensor([[1., 1., 1.],
# [1., 1., 1.]])
Overriding Data Type
If the input type is float and you want the output tensor type to be an integer, you can pass the dtype argument and set it to torch.int32.
import torch
input_tensor = torch.randn(2, 3, dtype=torch.float32)
ones_tensor = torch.ones_like(input_tensor, dtype=torch.int32)
print("Input Tensor dtype:", input_tensor.dtype)
# Output: Input Tensor dtype: torch.float32
print("Output Tensor dtype:", ones_tensor.dtype)
# Output: Output Tensor dtype: torch.int32
print("Output Tensor:\n", ones_tensor)
# Output: Output Tensor:
# tensor([[1, 1, 1],
# [1, 1, 1]], dtype=torch.int32)
That’s all!
