



The .full() method in PyTorch creates a tensor of a specified size filled with a provided scalar value. It supports integer, float, or complex numbers.
Whether you want to set biases, creating masks, or initializing weights in neural network, this method is helpful in achieving all of those things.
The torch.full() method is similar to torch.ones() or torch.zeros() method with the difference is that .ones() method creates a tensor filled with 1s, while the .zeros() method creates a tensor filled with 0s.
Syntax
torch.full(size,
fill_value,
out=None,
dtype=None,
layout=torch.strided,
device=None,
requires_grad=False)
Parameters
| Argument | Description |
| size (int) | It defines the shape of the output tensor. It can be a list or a tuple. (e.g., (2, 3) or [2, 3]). |
| fill_value (Scalar) |
It is a constant, scalar value to populate the tensor (e.g., 3, 3.14, 2.71, etc). |
| out (Tensor, optional) | It is an output tensor to store the result. By default, it is None. |
| dtype (torch.dtype, optional) | It determines the output tensor’s desired data type. It can be torch.float64, torch.int32, or torch.int64. By default, it is torch.int64. |
| layout (torch.layout, optional) | It is a layout of the output tensor. By default, it is torch.strided. It is rarely modified and in most cases, its value is by default. |
| device (torch.device, optional) | You can set the device to either torch.device(‘cpu’) or torch.device(‘gpu’). By default, it is set to the current device. |
| requires_grad (bool, optional) | If set to True, the output tensor requires gradient computation. By default, it is False. |
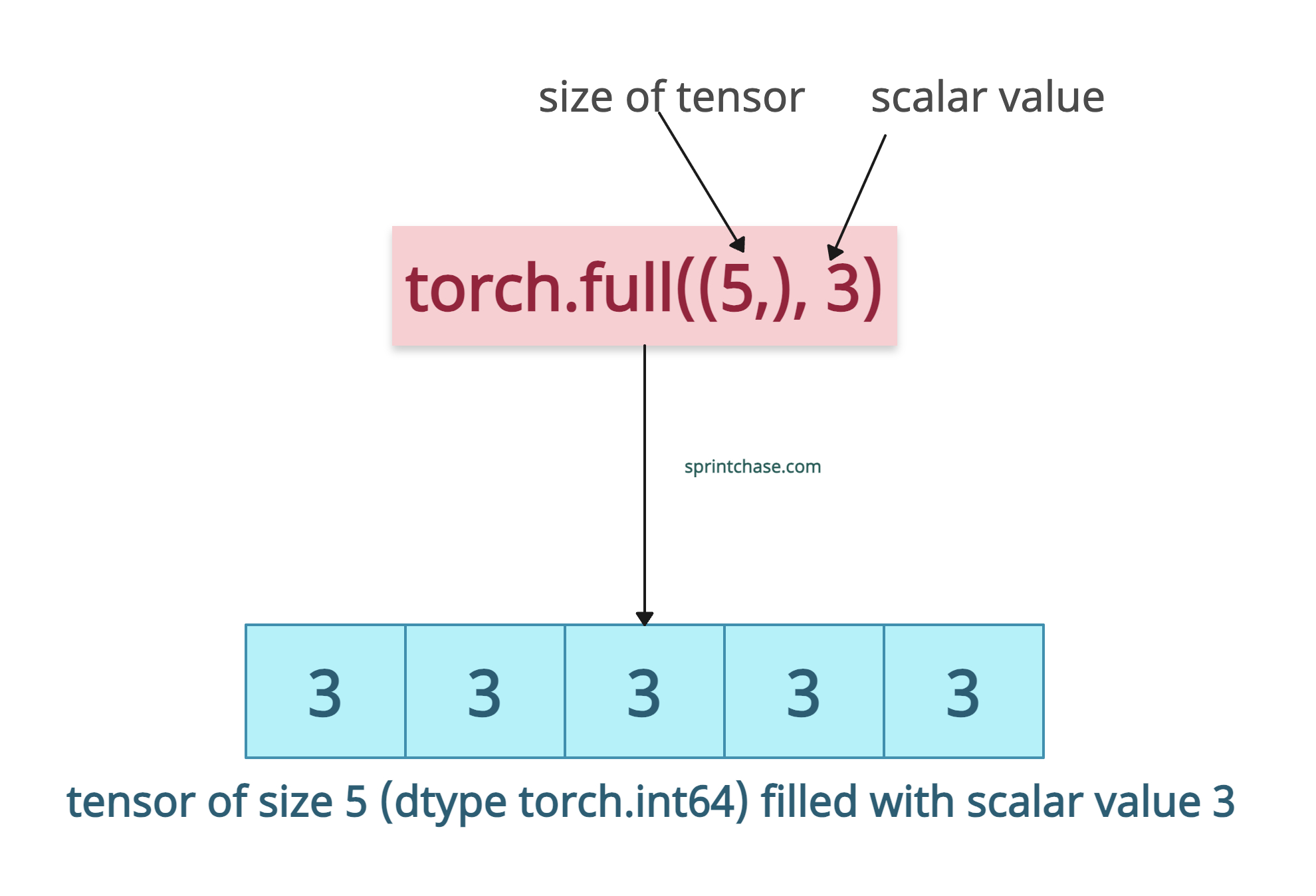
Creating a 1D tensor with a scalar value
Let’s create a 1D tensor of five values filled with 3s.
import torch # Create a 1D tensor filled with 3 tensor = torch.full((5,), 3) print(tensor) # Output: tensor([3, 3, 3, 3, 3])
The above code shows that we passed (5, ) as a shape because we created a 1D tensor with five elements, each of which is a scalar value of 3.
Generating a 2D tensor
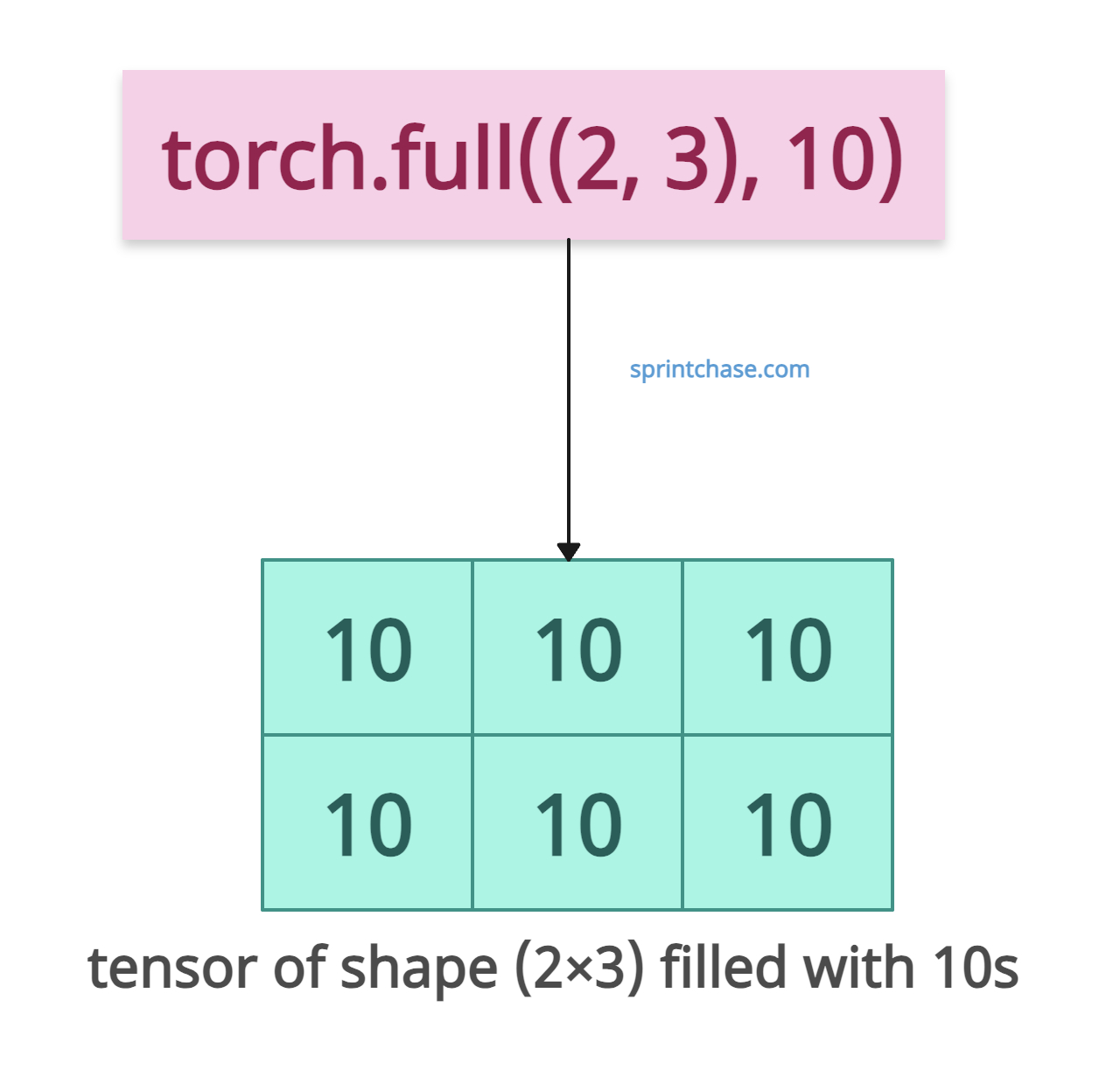
Let’s create a 2×3 tensor filled with the value 10.
import torch # Creating a 2D tensor filled with 10 tensor = torch.full([2, 3], 10) print(tensor) # Output: # tensor([[10, 10, 10], # [10, 10, 10]])
In the above code, we passed a list as the shape of the output tensor, which is 2×3. It generated a matrix filled with 10 values.
Specifying dtype

Let’s create a tensor of float64 type by passing dtype = torch.float64 argument with scalar 2.71 values.
import torch tensor = torch.full((6,), 3.14, dtype=torch.float64) print(tensor) # Output: tensor([3.1400, 3.1400, 3.1400, 3.1400, 3.1400, 3.1400], dtype=torch.float64)
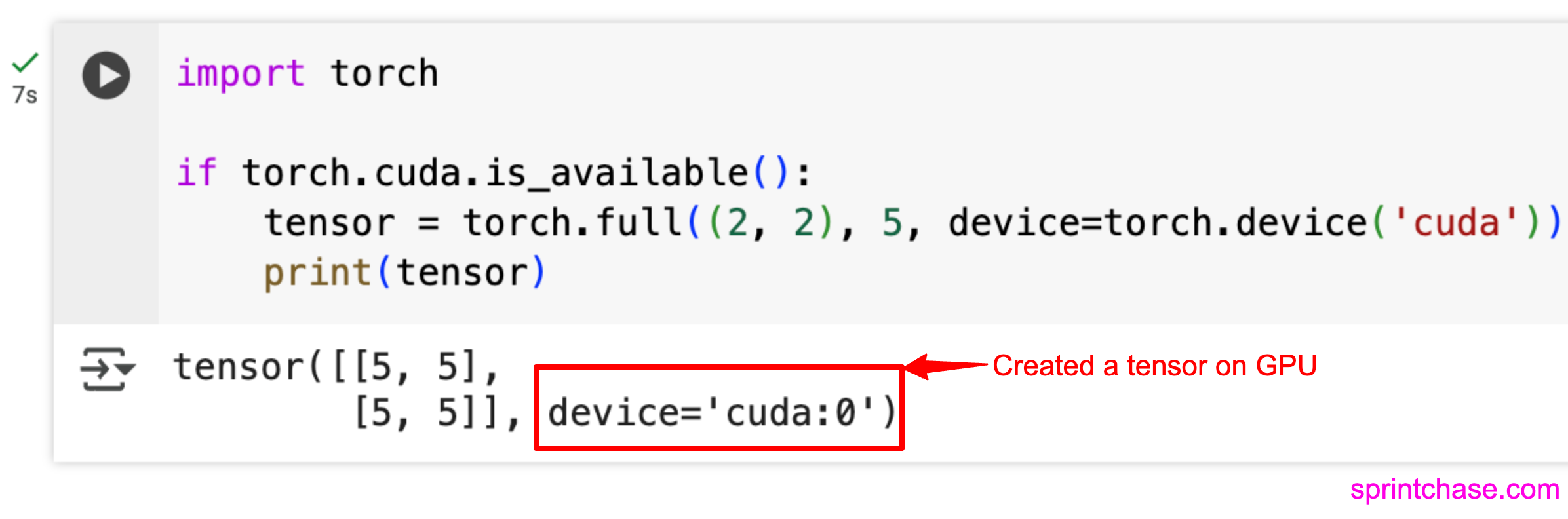
GPU tensor
Before creating a tensor on the GPU, make sure that your application is connected to it. On this blog, I wrote a guide on how to check if your PyTorch app is connected to a GPU.
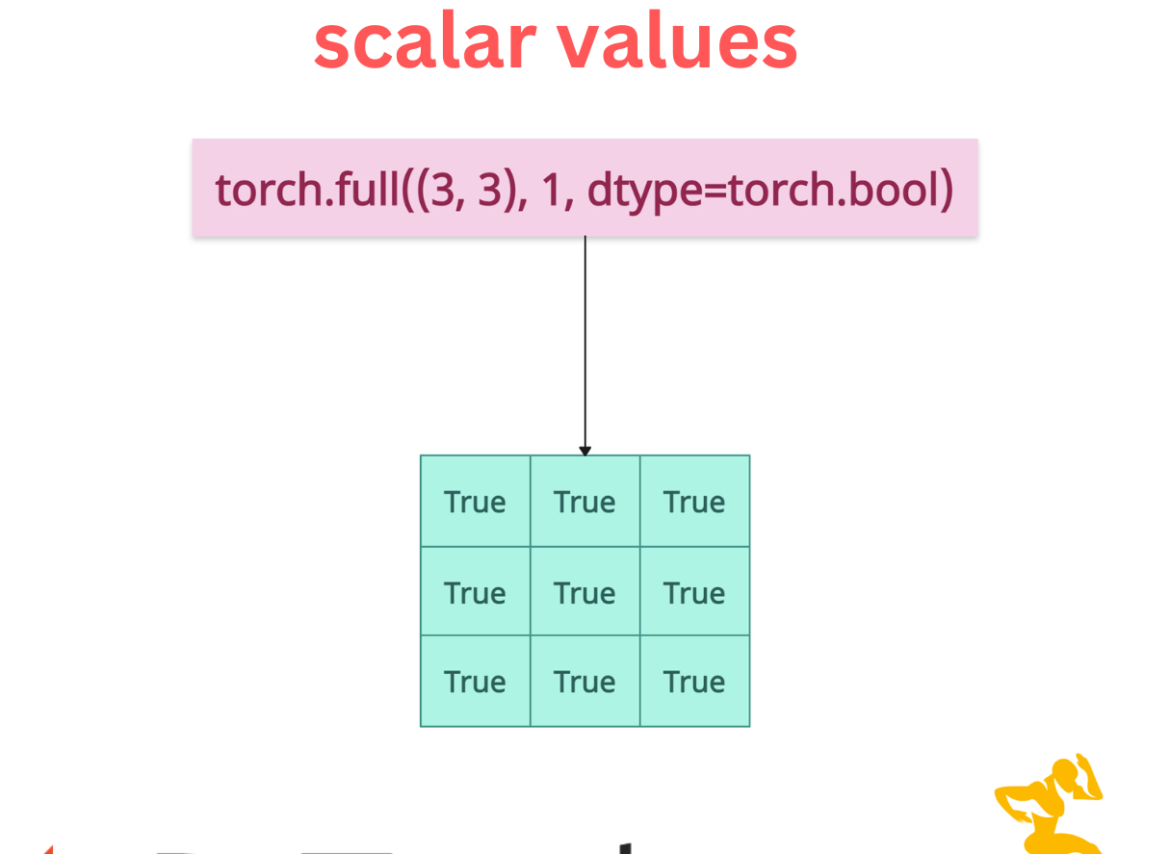
Creating Masks
We can create a binary mask by passing dtype = torch.boolean argument and pass 1 as a scalar value.
import torch mask = torch.full((3, 3), 1, dtype=torch.bool) print(mask) # Output: # tensor([[True, True, True], # [True, True, True], # [True, True, True]])
In Boolean, 1 is interpreted as True and 0 as False.
Using the “out” Parameter
You can create a pre-allocated tensor using torch.empty() method and then assign the .full() method’s results in this tensor to make it even more efficient.
Here, the pre-allocated tensor already exists, and you need to pass it in the “out” argument.import torch existing_tensor = torch.empty(2, 2) torch.full((2, 2), 9, out=existing_tensor) print(existing_tensor) # Output: # tensor([[9., 9.], # [9., 9.]])
Why is torch.full() more efficient?
The torch.full() is efficient because it eliminates the need for explicit for loops, which are typically slow due to Python’s interpreted nature and overhead.
Let’s test the performance by creating 10 million tensors on the GPU using below three approaches:
- torch.full(),
- For loop
- Broadcasting (e.g., torch.zeros() * value).
We will record the execution time for each of the three approaches to know which method is the fastest.
import torch
import time
# Define tensor size (large: 10 million elements)
size = (10_000_000,)
fill_value = 5.0
# Function to measure execution time
def measure_time(func, *args, desc=""):
start = time.time()
result = func(*args)
end = time.time()
print(f"{desc}: {end - start:.6f} seconds")
return result
# Approach 1: Using torch.full()
def using_full():
return torch.full(size, fill_value, dtype=torch.float32)
# Approach 2: Manual loop (filling tensor element by element)
def using_loop():
tensor = torch.empty(size, dtype=torch.float32)
for i in range(size[0]):
tensor[i] = fill_value
return tensor
# Approach 3: Broadcasting (using zeros and multiplication)
def using_broadcast():
return torch.zeros(size, dtype=torch.float32) + fill_value
# Run benchmarks
print(f"Creating tensor of size {size} with value {fill_value}")
measure_time(using_full, desc="torch.full")
measure_time(using_loop, desc="Manual loop")
measure_time(using_broadcast, desc="Broadcasting")
Here is the output of the test:

The above screenshot highlights the time taken by each approach.
- The .full() method is the fastest because it requires 0.04s.
- The second fastest approach is broadcasting, which takes 0.05s. Slightly slower than .full().
- The slowest approach is manual looping, which takes 45s, which is too much time, so it is the least efficient way.
