




torch.randn()
The torch.randn() is a factory method that generates a tensor with random numbers from a standard normal distribution (mean = 0, standard deviation = 1, variance = 1).
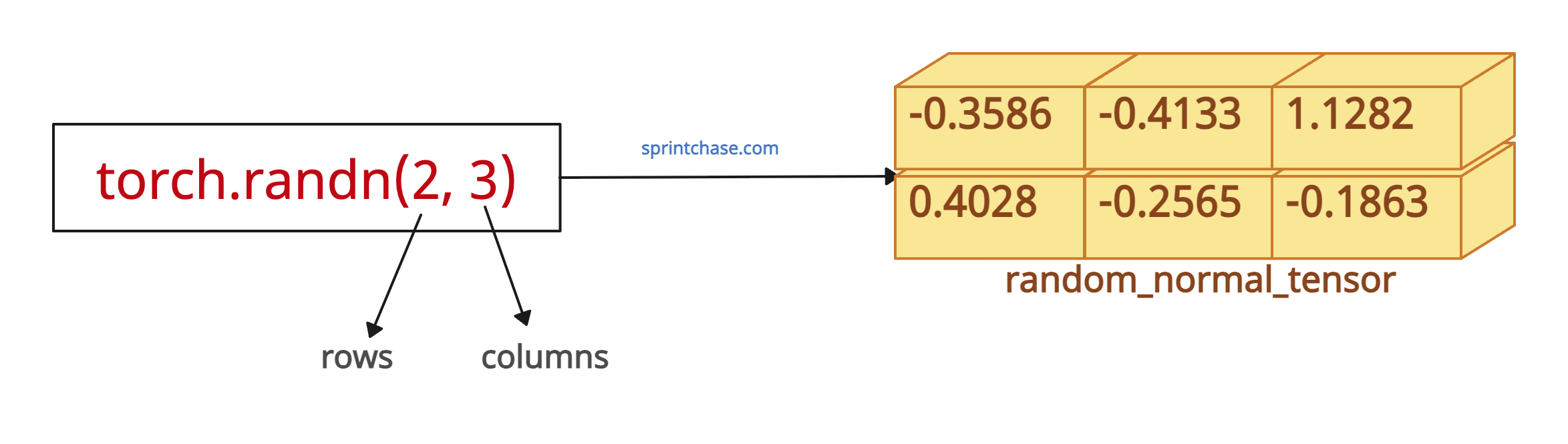
From the above figure, you can see that it returns a tensor of the specified shape with values sampled independently from a normal distribution.
Function Signature
torch.randn(*sizes,
out=None,
dtype=None,
layout=torch.strided,
device=None,
requires_grad=False) → Tensor
Arguments
| Name | Value |
| *sizes (int) | It determines the shape of the output tensor. |
| generator (torch.Generator, optional) | It defines a pseudorandom number generator for sampling. |
| out (Tensor, optional) | It is an output tensor into which we can write the results. It is an optional argument. The default is None. |
| dtype (torch.dtype, optional) | It determines the data type of the output tensor. By default, it is float. |
| layout (torch.layout, optional) | By default, it is torch.strided. It is a memory layout of the tensor. |
| device (torch.device, optional) | By default, it is a CPU. But you can change it to “cuda:0” using this argument. |
| requires_grad (bool, optional) | By default, it is False. If you set it to True, it will calculate the gradient for this tensor. |
| pin_memory (bool, optional) | By default, it is False. If set to True, the returned tensor would be allocated in the pinned memory. |
Basic random tensor generation
Let’s generate a random 2×3 tensor with standard normal values:import torch random_normal_tensor = torch.randn(2, 3) print(random_normal_tensor) # Output: # tensor([[-0.3586, -0.4133, 1.1282], # [ 0.4028, -0.2565, 0.3398]])
Reproducibility with seed
You can control the randomness to achieve deterministic results using torch.manual_seed() method.
import torch torch.manual_seed(42) random_normal_tensor = torch.randn(2, 3) print(random_normal_tensor) # Output: # tensor([[ 0.3367, 0.1288, 0.2345], # [ 0.2303, -1.1229, -0.1863]]) # tensor([[ 0.3367, 0.1288, 0.2345], # [ 0.2303, -1.1229, -0.1863]]) # tensor([[ 0.3367, 0.1288, 0.2345], # [ 0.2303, -1.1229, -0.1863]])
You can see that I have executed multiple times, and each time it gives the same output. That means we can generate the exact same random numbers repeatedly.
Specifying Shape (*sizes)
You can pass the required shape either as integers or in a tuple or list format.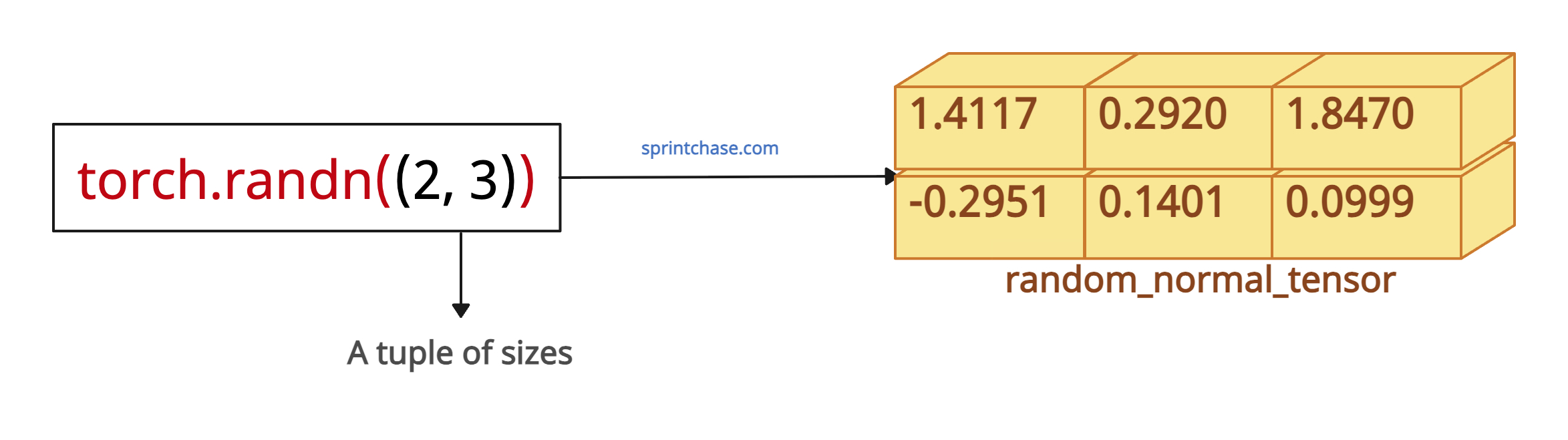 Let’s pass a tuple of sizes:
Let’s pass a tuple of sizes:
import torch # Size passed a single tuple random_normal_tensor = torch.randn((2, 3)) print(random_normal_tensor) # Output: # tensor([[ 1.4117, 0.2920, 1.8470], # [-0.2951, 0.1401, 0.0999]])Let’s pass a list of sizes:
import torch # Size passed a single tuple random_normal_tensor = torch.randn([2, 3]) print(random_normal_tensor) # Output: # tensor([[ 1.4117, 0.2920, 1.8470], # [-0.2951, 0.1401, 0.0999]])
Writing into an existing tensor using “out” argument
From function arguments, we can use the “out” argument to write the result in a pre-allocated tensor.
For that, you have to create an empty tensor first using torch.empty() method:import torch pre_allocated = torch.empty(3, 2) print(pre_allocated) # Output: # tensor([[0., 0.], # [0., 0.], # [0., 0.]]) torch.randn(3, 2, out=pre_allocated) print(pre_allocated) # Output: # tensor([[-0.1070, -0.8163], # [-0.5375, -0.1606], # [ 0.1432, 0.4633]])
You can see that we did not write a new variable to assign the output tensor. Instead, we wrote the values into an existing tensor, which is “pre-allocated”.
One thing to make sure of is that the “out” tensor should have the same shape as the tensor you are randomly generating.
Changing dtype
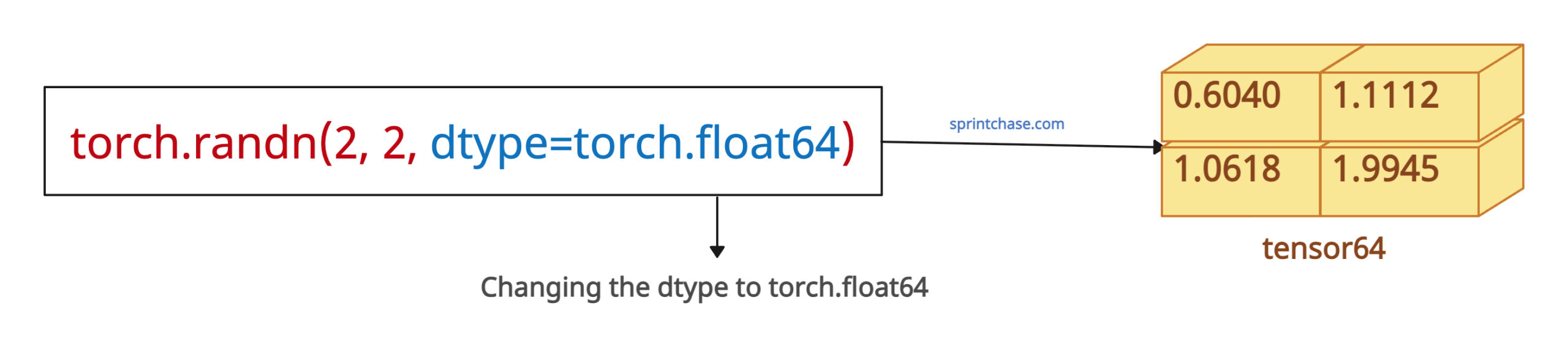
You can control the output tensor’s type from the default torch.float32 to torch.float64 and torch.float16.
import torch tensor64 = torch.randn(2, 2, dtype=torch.float64) print(tensor64) # Output: # tensor([[0.6040, 1.1112], # [1.0618, 1.9945]], dtype=torch.float64) tensor16 = torch.randn(2, 2, dtype=torch.float16) print(tensor16) # Output: # tensor([[-0.3452, 0.0709], # [-0.5215, -0.4639]], dtype=torch.float16)
Non‑floating dtypes (e.g. torch.int32) are not supported and will raise RuntimeError: “normal_kernel_cpu” not implemented for ‘Long’:
import torch tensorint64 = torch.randn(2, 2, dtype=torch.int64) print(tensorint64) # Output: RuntimeError: "normal_kernel_cpu" not implemented for 'Long'
Specifying device
You can generate directly on the GPU by specifying device = “cuda:0”.import torch
cpu_tensor = torch.randn(4, 4, device="cpu")
print(cpu_tensor.device)
# Output: cpu
# On GPU (if available)
if torch.cuda.is_available():
gpu_tensor = torch.randn(4, 4, device="cuda:0")
print(gpu_tensor.device) # → cuda:0
Tracking Gradients by requires_grad
You can control that the output tensor is part of an autograd tensor by passing requires_grad = True.import torch # With gradient tracking t2 = torch.randn(3, 3, requires_grad=True) print(t2) # Output: # tensor([[-2.3310, 0.7982, 0.7574], # [ 0.1524, -0.2317, 0.6158], # [-0.3591, -1.5899, 0.2003]], requires_grad=True) print(t2.requires_grad) # Output: True
torch.randn_like()
The torch.randn_like() method generates a tensor filled with random numbers from a standard normal distribution (mean 0, variance 1), matching the size, data type (dtype), and device of an input tensor.
Syntax
torch.randn_like(input,
dtype=None,
layout=None,
device=None,
requires_grad=False,
memory_format=torch.preserve_format)
Parameters
| Argument | Description |
| input (Tensor) | It represents an input tensor. |
| dtype (torch.dtype, optional) | It overrides the data type of the output tensor. |
| layout (torch.layout, optional) |
It specifies the memory layout. It defaults to the layout of the input tensor. |
| device (torch.device, optional) |
It represents the device. Either CPU or CUDA. |
| requires_grad (bool, optional) |
If it is True, the output tensor tracks gradients for autograd. The default is False. |
| memory_format (torch.memory_format, optional) |
It defines the memory format for the output tensor. |
Basic usage of randn_like()
import torch input_tensor = torch.ones(2, 3) # Shape: (2, 3), dtype: float32, device: CPU random_like_tensor = torch.randn_like(input_tensor) print(random_like_tensor) # Output: # tensor([[-0.0073, 1.1260, 0.8394], # [ 1.5084, 0.4193, -0.3740]])
In this code, we first created a tensor using the tensor.ones() method, which you can take as a pre-allocated tensor and then fill it with random numbers from a normal distribution (𝒩(0, 1), i.e., mean = 0, std = 1).
The output tensor has shape (2, 3), dtype float32.Reproducibility with Seed
With the help of a torch.manual_seed() method to ensure consistent random values.
import torch torch.manual_seed(42) input_tensor = torch.ones(2, 2) random_tensor1 = torch.randn_like(input_tensor) torch.manual_seed(42) # Reset seed random_tensor2 = torch.randn_like(input_tensor) print(random_tensor1 == random_tensor2) # Output:tensor([[True, True], # [True, True]])
Using the double equals operator (==), we compare the two tensors to determine if they are equal or not. Since the output contains True values, it means both tensors are the same after specifying the seed.
