




The torch.nanmean() method calculates the arithmetic mean of all non-NaN (Not a Number) elements in a tensor along a specified dimension or over the entire tensor. This method counts NaN values as zero and ignores them completely.
It is different from a torch.mean() method, which includes NaN values and may return NaN if any element is NaN, while torch.nanmean() method provides a robust alternative by excluding NaN values.
Syntax
torch.nanmean(input, dim=None, keepdim=False, dtype=None, out=None)
Parameters
| Argument | Description |
| input (Tensor) | It is an input tensor that contains elements whose mean you want to find, and it may contain NaN values. |
| dim (int or tuple of ints, optional) |
It is the dimension(s) along which to calculate the mean. |
| keepdim (bool, optional) |
If it is True, it retains the reduced dimension(s) as size 1 in the output tensor. |
| dtype (torch.dtype, optional) |
It is the desired data type of the output tensor. You cannot define an int32 or int64 because it won’t be compatible with this method. |
| out (Tensor, optional) |
It is an optional output tensor to store the result. By default, it is None. If you have a pre-allocated tensor, this is very helpful. |
Mean of an entire tensor
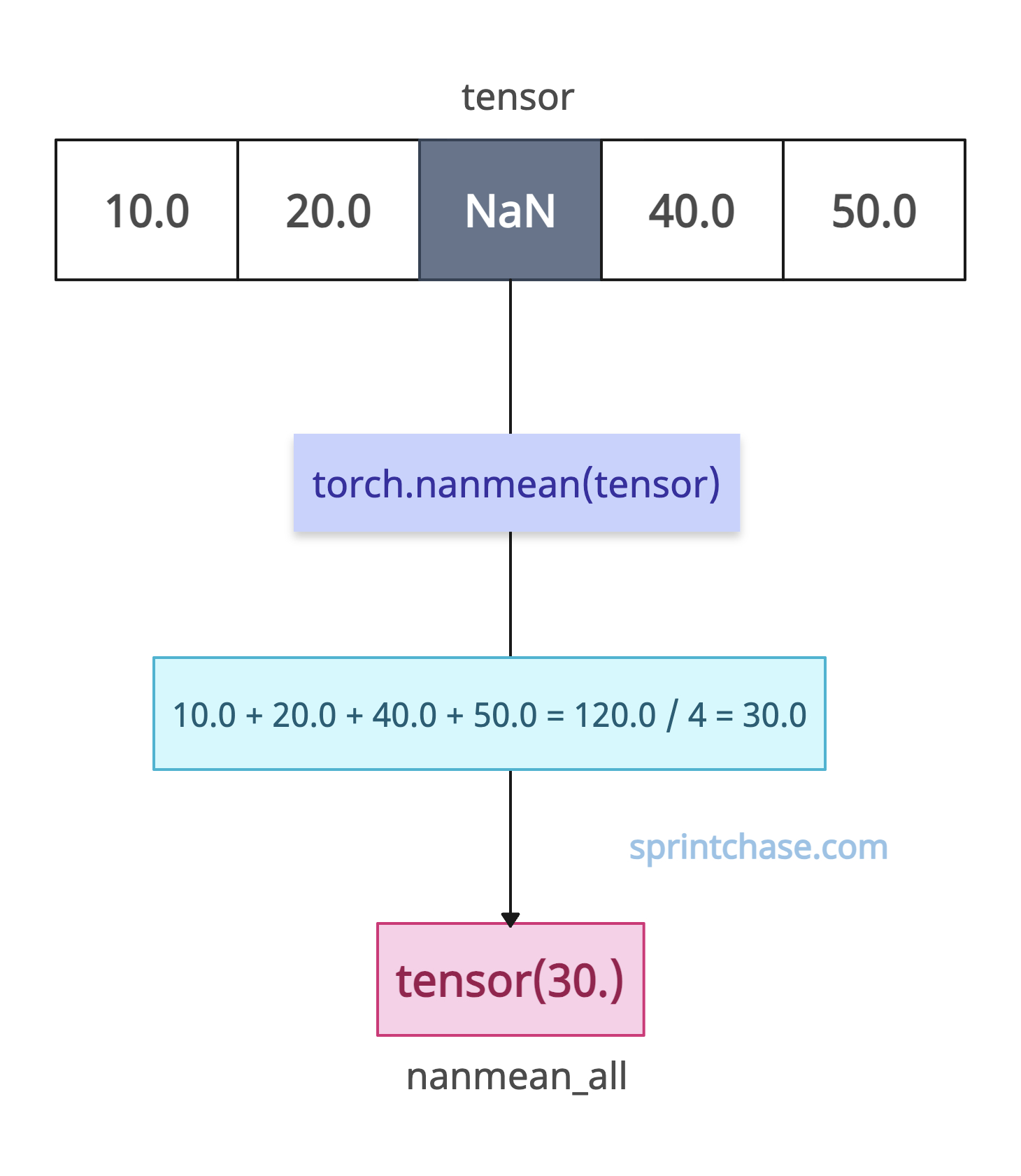
Let’s say we have a 1D tensor containing NaN values.
import torch
tensor = torch.tensor([10.0, 20.0, float('nan'), 40.0, 50.0])
nanmean_all = torch.nanmean(tensor)
print(nanmean_all)
# Output: tensor(30.)
The torch.nanmean() method calculatess the mean as (10.0 + 20.0 + 40.0 + 50.0) / 4 = 30.0.
Along a specific dimension

If you are working with multi-dimensional tensors, you can calculate the mean along a specific dimension.
Let’s calculate nanmean when dim = 1.
import torch
tensor = torch.tensor([[11.0, float('nan'), 31.0],
[41.0, 51.0, float('nan')]])
nanmean_dim = torch.nanmean(tensor, dim=1)
print(nanmean_dim)
# Output: tensor([21., 46.])
For dim=1, the mean is computed along each row:
- Row 1: [11.0, nan, 31.0] → (11. + 31.) / 2 = 21.0
- Row 2: [41.0, 51.0, nan] → (41. + 51.) / 2 = 46.0
dim = 0

When you calculate along a row, it will go column-wise. This means the first value of the first row and the first value of the second row will be compared.
import torch
tensor = torch.tensor([[11.0, float('nan'), 31.0],
[41.0, 51.0, float('nan')]])
nanmean_row = torch.nanmean(tensor, dim=0)
print(nanmean_row)
# Output: tensor([26., 51., 31.])
For dim=0, the mean is calculated along each column:
- Column 1: [11.0, 41.0] → (11. + 41.) / 2 = 26.0
- Column 2: [nan, 51.0] → (51.) / 1 = 51.0
- Column 3: [31.0, nan] → (31.) / 1 = 46.0
Using keepdim=True
We can retain the reduced dimension as size 1 in the output tensor.
import torch
tensor = torch.tensor([[1.0, float('nan'), 3.0],
[4.0, 5.0, float('nan')]])
nanmean_keepdim = torch.nanmean(tensor, keepdim=True, dim=1)
print(nanmean_keepdim)
# Output:
# tensor([[2.0000],
# [4.5000]])
As shown in the above program, the output tensor retains the reduced dimension (size 1), resulting in a shape of (2, 1) instead of (2, ).
RuntimeError: “nansum_cpu” not implemented for ‘Int’
The dtype=torch.int32 argument is invalid for torch.nanmean(). You cannot use int32 or int64 data types.
This method requires a floating-point data type (float32, float64, etc.) because it involves division and potentially produces fractional results.
import torch
tensor = torch.tensor([1.0, float('nan'), 3.0], dtype=torch.float32)
nanmean_result = torch.nanmean(tensor, dtype=torch.int32)
print(nanmean_result)
# RuntimeError: "nansum_cpu" not implemented for 'Int'
Don’t use incompatible data types!
Handling tensor with all NaN values
If all elements in a tensor are NaN, the output is NaN.
import torch
tensor = torch.tensor([float('nan'), float('nan')])
nanmean_result = torch.nanmean(tensor)
print(nanmean_result)
# Output: tensor(nan)
Since all elements are NaN, the output is NaN too. 