




PyTorch empty() method creates a tensor of specified shape, filled with uninitialized data. The output tensor’s memory is allocated but not zeroed or filled; it contains arbitrary values.

However, if you are operating this method on a modern OS, you may get a zeroed output, but it is due to your OS settings and not through torch.empty() method.
It avoids computational overhead by initializing with zeros, making it more efficient.
Syntax
torch.empty(
*size,
dtype=None,
layout=torch.strided,
device=None,
requires_grad=False,
pin_memory=False,
memory_format=torch.contiguous_format
) → Tensor
Parameters
| Argument | Description |
| size (int) | It determines the shape of the output tensor. (e.g., 2, 3, or (2, 3, 4)). It can be a variable number of arguments, a list, or a tuple of sizes. |
| out (Tensor, optional) | It defines the output tensor. |
| dtype (torch.dtype, optional) | It defines the type of the output tensor, e.g., torch.float64, torch.int64. By default, it is set to the global type, torch.float32. |
| layout (torch.layout, optional) | It is a memory layout. By default, it is torch.strided. |
| device (torch.device, optional) | It states the device on which to allocate. By default, it is ‘cpu’, but you can set it to GPU using ‘cuda:0’. |
| required_grad (bool, optional) | By default, it is False, but to enable gradient computation, set it to True. |
| pin_memory (bool, optional) | By default, it is False. However, if you set it to True, the returned tensor would be allocated in the pinned memory. It only works for CPU tensors. |
| memory_format (torch.memory_format, optional) | It controls the contiguous or channels-last format. |
Simple tensor allocation
import torch empty_tensor = torch.empty((2, 3)) print(empty_tensor)
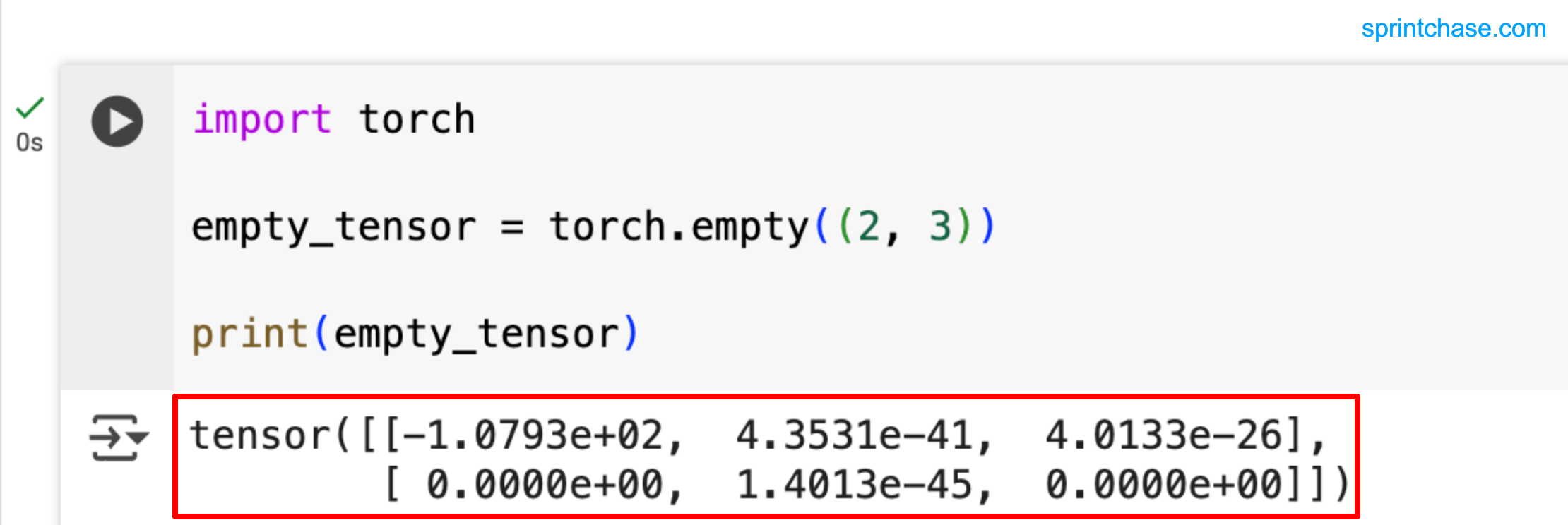
If you are working on a Modern OS, then you might not get arbitrary values at all. Instead, you will get all the values 0.
On the CPU, PyTorch’s allocator typically requests fresh memory pages from the operating system (via mmap). For security reasons, the OS gives you pages that have already been zeroed.
Although torch.empty() method itself does not write zeros; the memory you receive happens to contain zeros.
import torch empty_tensor = torch.empty((2, 3)) print(empty_tensor) # Output: # tensor([[0., 0., 0.], # [0., 0., 0.]])
I covered both scenarios, depending on the environment you’re using currently!
Shape specification
You can specify the output shape in multiple ways. For example, you can pass integers, a list, or a tuple of sizes.
import torch # Separate integer arguments empty_simple = torch.empty(2, 3) print(empty_simple) # Output: # tensor([[1.2211e-40, 0.0000e+00, 0.0000e+00], # [0.0000e+00, 4.0064e-26, 0.0000e+00]]) # Single tuple argument empty_tensor_by_tuple = torch.empty((2, 3)) print(empty_tensor_by_tuple) # Output: # tensor([[4.0091e-26, 0.0000e+00, 4.0091e-26], # [0.0000e+00, 1.4013e-45, 2.8026e-45]]) # Single list argument empty_tensor_by_list = torch.empty([2, 3]) print(empty_tensor_by_list) # Output: # tensor([[4.0220e-26, 0.0000e+00, 0.0000e+00], # [2.3510e-38, 2.7561e-29, 0.0000e+00]]) # Using torch.Size shape = torch.Size([2, 3]) empty_tensor_by_size = torch.empty(shape) print(empty_tensor_by_size) # Output: # tensor([[4.0109e-26, 0.0000e+00, 4.0097e-26], # [0.0000e+00, 4.0106e-26, 7.0065e-45]])
Again, if you’re running on a modern OS, you’ll see only zero values.
Controlling output dtype
By default, it has torch.float32. However, you can control it using the dtype argument.
You can create an output of integer or boolean tensors.
import torch # Integer tensor int_tensor = torch.empty(2, 2, dtype=torch.int64) print(int_tensor) # Output: tensor([[ 356984855, 4294967296], # [ 0, 113]]) print(int_tensor.dtype) # Output: torch.int64 # Boolean tensor bool_tensor = torch.empty(2, 2, dtype=torch.bool) print(bool_tensor) # Output: # tensor([[True, True], # [True, False]]) print(bool_tensor.dtype) # Output: torch.bool
Allocating device
Let’s allocate to the GPU by setting device=’cuda:0′.
import torch cuda_tensor = torch.empty(3, 3, device='cuda:0') print(cuda_tensor) # Output: # tensor([[3.5178e-26, 0.0000e+00, 1.3591e+22], # [6.6762e+22, 1.7584e-04, 3.3608e+21], # [1.3177e-08, 1.6691e+22, 2.6705e+23]]) print(cuda_tensor.device) # Output: cuda:0
If you are not on a GPU, you will get this error: AssertionError: Torch not compiled with CUDA enabled. So, make sure you’re on a GPU.
Enable gradient tracking
If you set requires_grad = True, gradient tracking will be enabled.
import torch grad_tensor = torch.empty(2, 2, requires_grad=True) print(grad_tensor) # Output: # tensor([[-1.0793e+02, 4.3531e-41], # [-1.0793e+02, 4.3531e-41]], requires_grad=True)
Pinning CPU memory
You can pin the CPU memory for the faster hosts. If you are on a basic laptop like me, don’t pin the memory. Only pin when CUDA is available.
import torch unpinned = torch.empty(4, 4, pin_memory=False) print(unpinned.is_pinned()) # Output: False # Pinned memory use_pin = torch.cuda.is_available() pinned = torch.empty(2, 3, pin_memory=use_pin) print(pinned.is_pinned()) # Output: True
If you are not on CUDA, you will get the last output as False. Don’t request pin_memory on CPU-only builds.
Standard contiguous layout
By default, memory_format=torch.contiguous_format on PyTorch but you can change it to memory_format=torch.channels_last.
import torch # Standard contiguous format (default) contig = torch.empty(1, 3, 224, 224, memory_format=torch.contiguous_format) print(contig.is_contiguous()) # Output: True # Channels-last (NHWC) format cl = torch.empty(1, 3, 224, 224, memory_format=torch.channels_last) print(cl.data_ptr() % 4 == 0) # Output: True
Tensor layout
If you set for layout=torch.sparse_coo, PyTorch routes you to the sparse‐COO constructor instead of erroring, and it returns an empty sparse‐COO tensor (i.e., zero nonzeros, nnz=0).
import torch sparse_tensor = torch.empty(2, 2, layout=torch.sparse_coo) print(sparse_tensor) # Output: # tensor(indices=tensor([], size=(2, 0)), # values=tensor([], size=(0,)), # size=(2, 2), nnz=0, layout=torch.sparse_coo)That’s all!
