




The torch.chunk() method splits a tensor into a specified number of chunks along a provided dimension. Each chunk is a view (not a copy) of the original tensor, meaning modifications to a chunk reflect in the original tensor.
The output tensor is a tuple of Tensor objects, representing a chunk of the input tensor.
Syntax
torch.chunk(input, chunks, dim=0)
Parameters
| Argument | Description |
| input (Tensor) | It represents an input tensor that will be split. |
| chunks (int) | It represents how many chunks are to be produced.
If the tensor size along the specified dimension is not divisible by chunks, the last chunk may be smaller. |
| dim (int, optional) |
It is the dimension along which the tensor is split. The default is 0. The dimension can be negative. If that is the case, then it follows the basic Python indexing. For example, if -1, it will start from the end of the tensor. |
Basic chunking
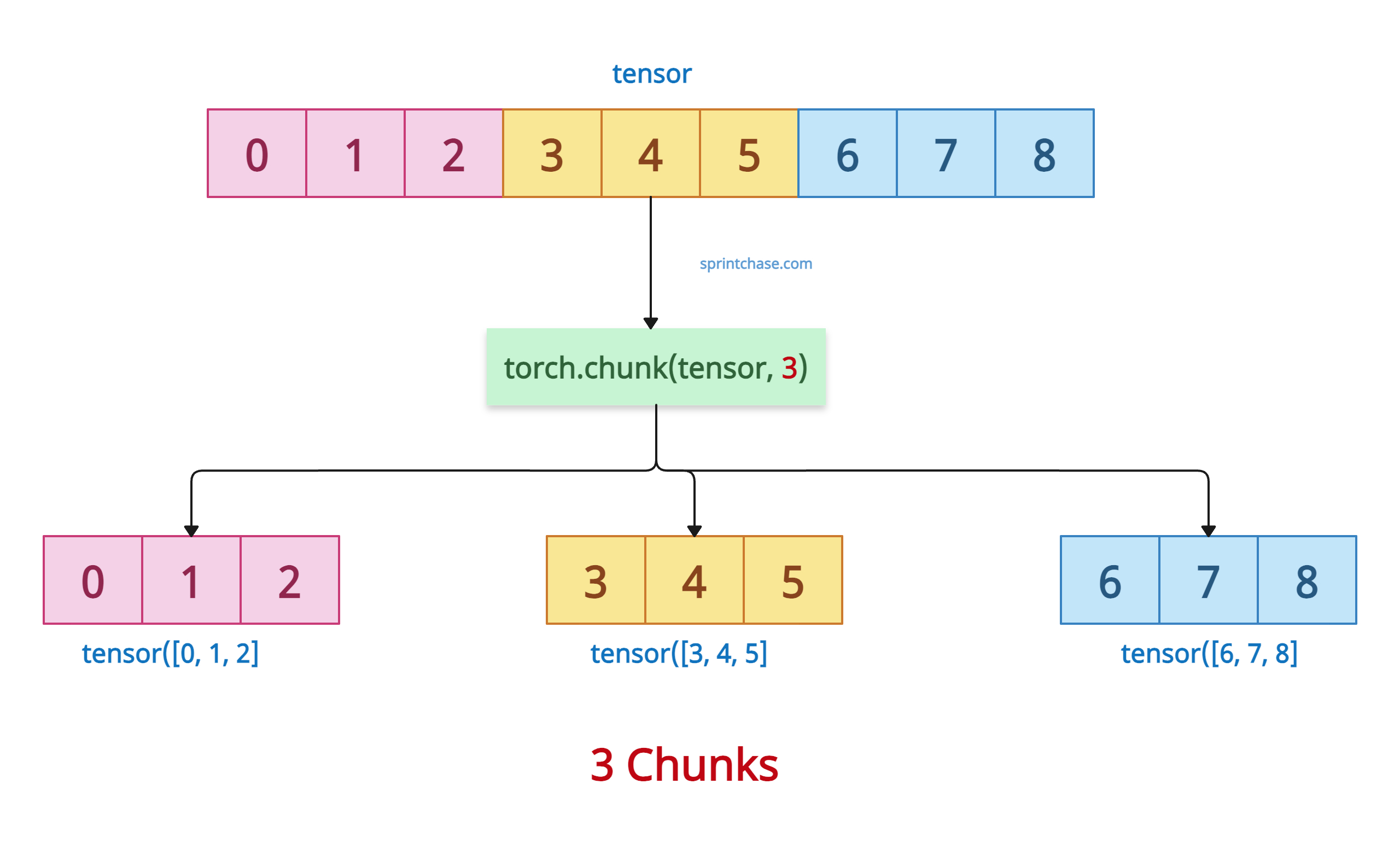
Let’s create a sequence of 9 elements using the torch.arange() method and then divide the tensor into 3-3-3 chunks.
import torch tensor = torch.arange(9) print(tensor) # Output: tensor([0, 1, 2, 3, 4, 5, 6, 7, 8]) chunks = torch.chunk(tensor, 3) # Split into 3 chunks along dim=0 print(chunks) # Output: (tensor([0, 1, 2]), tensor([3, 4, 5]), tensor([6, 7, 8]))
The above output is a tuple of tensors. Each tensor contains exactly three elements.
Here, you can see that the dimension size is perfectly divisible by the chunks. All chunks have size dim_size // chunks.
What if the dimension size is not divisible by chunks? For example, our input tensor contains 10 elements, and the chunk size is 3. That means each chunk should have 10/3 = 3.333. But that is not possible.
In this case, the first (dim_size % chunks) chunks have (dim_size // chunks) + 1 elements, and the rest have dim_size // chunks.
Let me demonstrate with a coding example:
import torch tensor = torch.arange(10) print(tensor) # Output: tensor([0, 1, 2, 3, 4, 5, 6, 7, 8, 9]) chunks = torch.chunk(tensor, 3) # Split into 3 chunks along dim=0 print(chunks) # Output: (tensor([0, 1, 2, 3]), tensor([4, 5, 6, 7]), tensor([8, 9]))
Based on our logic, the first two chunks contain four elements, which is (chunk_size (3) + 1). The last chunk has the remaining two elements. Still, the total number of chunks is three, but the chunk size differs.
Chunking a 2D tensor along a specific dimension
Chunking column-wise
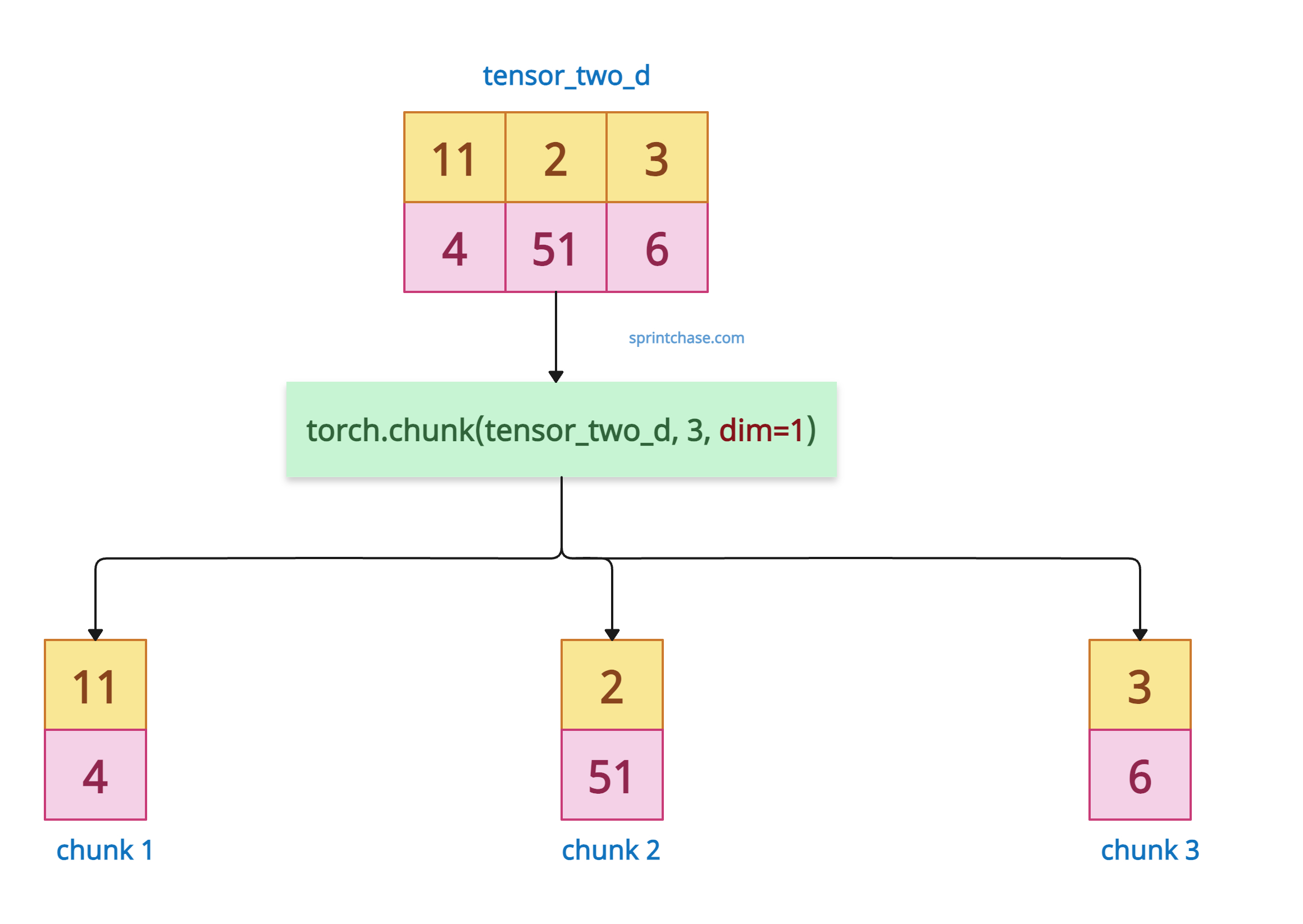 The 2D tensor contains rows and columns. Passing dim=1 will split the tensor columnwise.
The 2D tensor contains rows and columns. Passing dim=1 will split the tensor columnwise.
import torch
tensor_two_d = torch.tensor([[11, 2, 3], [4, 51, 6]])
column_chunks = torch.chunk(tensor_two_d, 3, dim=1) # Split columns
for chunk in column_chunks:
print(chunk)
# Output:
# tensor([[11],
# [ 4]])
# tensor([[ 2],
# [51]])
# tensor([[3],
# [6]])
The above output splits the tensor into three chunks, each containing single-column values.
Chunking row-wise
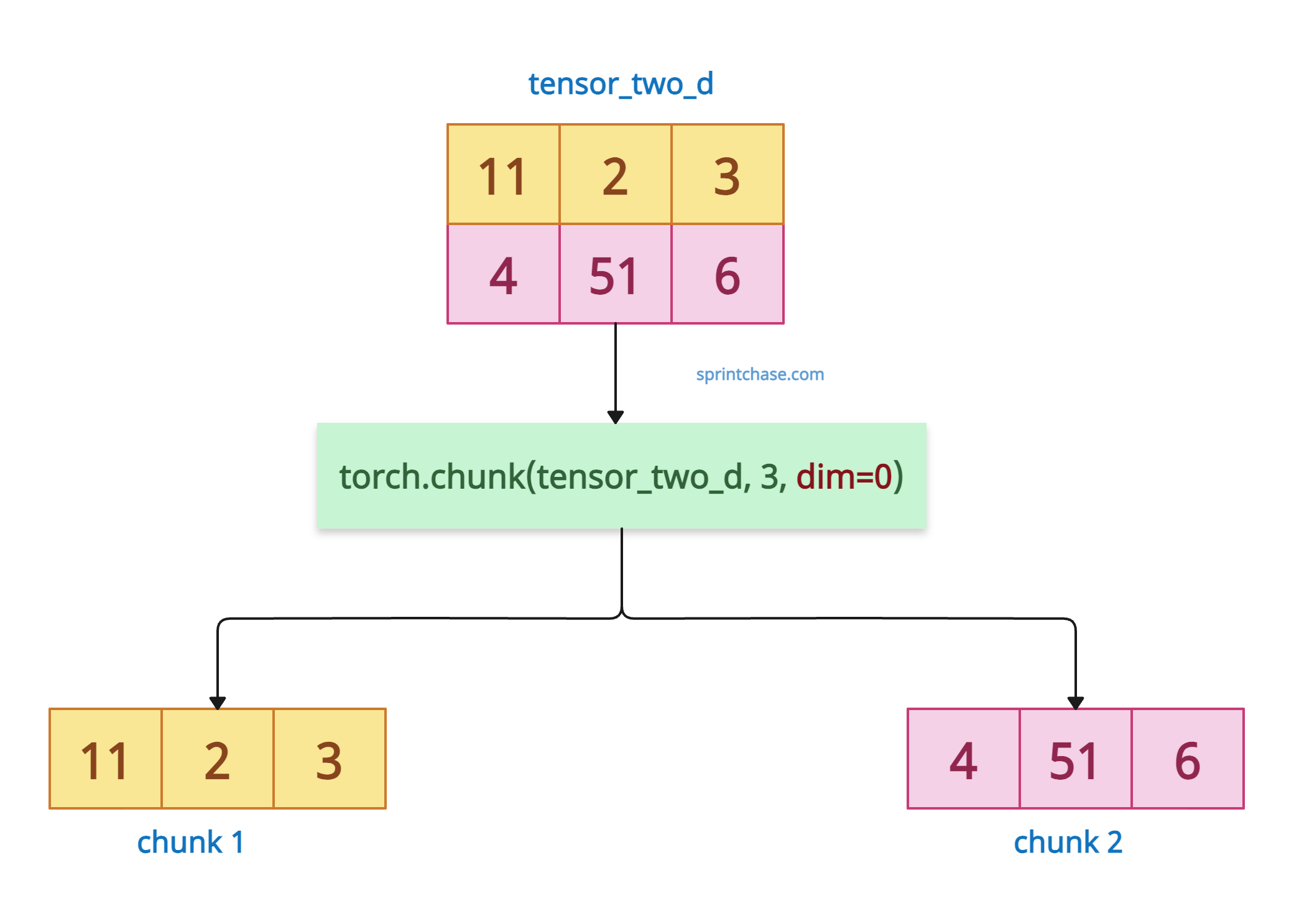
To chunk a 2D tensor row-wise, pass the dim=0.
import torch
tensor_two_d = torch.tensor([[11, 2, 3], [4, 51, 6]])
row_chunks = torch.chunk(tensor_two_d, 2, dim=0) # Split rows
for chunk in row_chunks:
print(chunk)
# Output:
# tensor([[11, 2, 3]])
# tensor([[ 4, 51, 6]])
In the above code, we divided the tensor into two equal row chunks. Each chunk contains 3 elements, so 3×2 = 6. The total number of elements remains the same.
Modifying Chunks (View Behavior)
After creating chunks, let’s modify the chunk(s) and check the original tensor to see if it reflects the changes.
import torch
print("Before modifying the chunks: ")
tensor_two_d = torch.tensor([[11, 2, 3], [4, 51, 6]])
print(tensor_two_d)
row_chunks = torch.chunk(tensor_two_d, 2, dim=0)
print(row_chunks)
row_chunks[0][0, 0] = 1
print("After modifying the chunks: ")
print(row_chunks)
print(tensor_two_d)
# Output:
# Before modifying the chunks:
# tensor([[11, 2, 3],
# [ 4, 51, 6]])
# (tensor([[11, 2, 3]]), tensor([[ 4, 51, 6]]))
# After modifying the chunks:
# (tensor([[1, 2, 3]]), tensor([[ 4, 51, 6]]))
# tensor([[ 1, 2, 3],
# [ 4, 51, 6]])
In the above code, we created a chunk of the 2D tensor row-wise. Each chunk contains three elements.
The first element of the first chunk is 11. We will now modify its value from 11 to 1.
Now, let’s check out the original tensor. Yes, you can see that it also gets modified, and now the original tensor’s first element is 1.
Here, we can prove that if you modify the chunk, it will reflect in the original tensor.
Comparison with torch.split()
The main difference between torch.chunk() and torch.split() is that .chunk() divides the input tensor into roughly equal parts, while .split() allows precise size specification for each segment.
import torch tensor = torch.arange(10) # Using chunk chunked = torch.chunk(tensor, 3) print(chunked) # Output: (tensor([0, 1, 2, 3]), tensor([4, 5, 6, 7]), tensor([8, 9])) # Using split split = torch.split(tensor, [3, 4, 3]) # Specify sizes print(split) # Output: (tensor([0, 1, 2]), tensor([3, 4, 5, 6]), tensor([7, 8, 9]))
Handling edge cases
If you pass the size of the chunk <= 0, it will throw RuntimeError: chunk expects `chunks` to be greater than 0, got: 0.
import torch tensor = torch.arange(9) chunked = torch.chunk(tensor, 0) print(chunked) # Output: RuntimeError: chunk expects `chunks` to be greater than 0, got: 0
Make sure to pass a positive number chunk size greater than 0.
If you pass the chunk size 1, it will return a single chunk containing the original tensor.
import torch tensor = torch.arange(9) chunked = torch.chunk(tensor, 1) print(chunked) # Output: (tensor([0, 1, 2, 3, 4, 5, 6, 7, 8]),)That’s all!
