



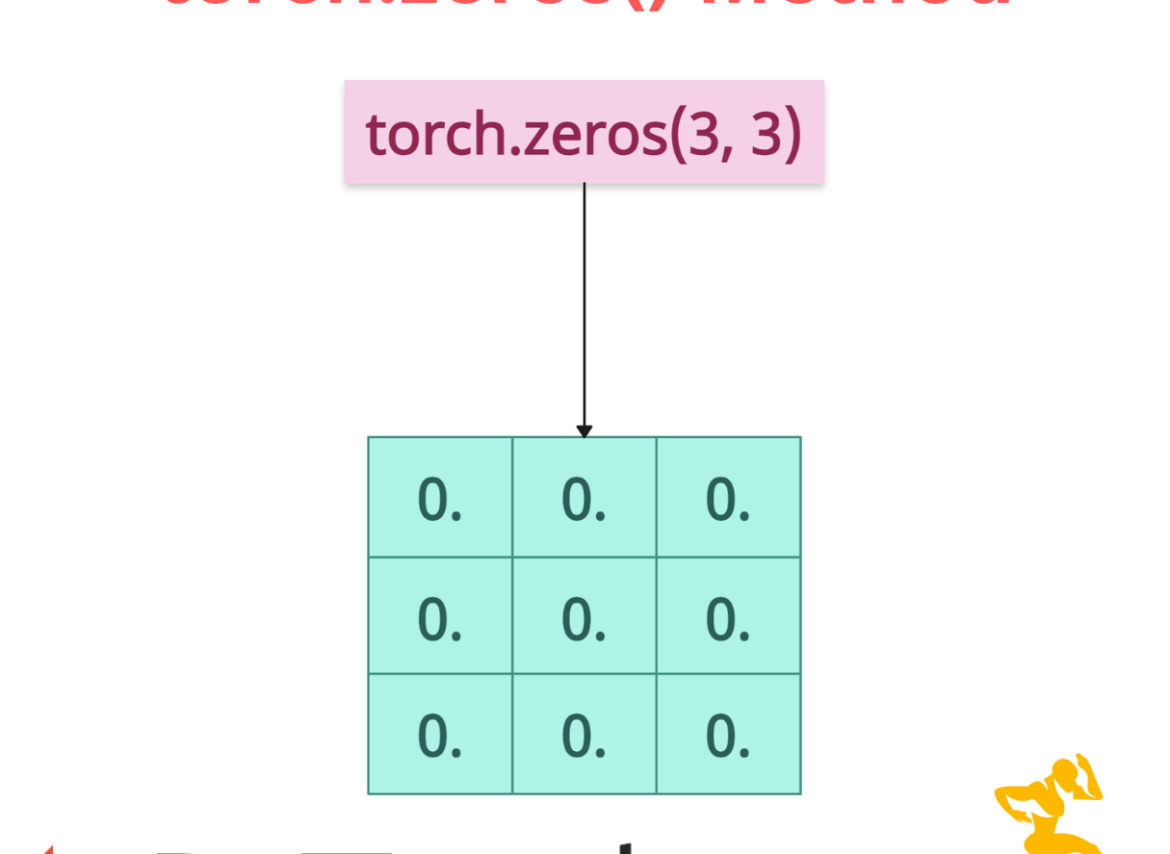
The torch.zeros() method creates a tensor filled with zeros. You can use the .zeros() method in parameter initialization, masking, and memory preallocation. It supports multi-dimensional tensors, various data types, and device placement (CPU/GPU).
For example, if I want to pre-allocate a tensor whose values are future-dependent, I can create one tensor now filled with zeros, and later, when the values arrive, I will assign them to this pre-allocated tensor.
Pytorch empty() is also a similar kind of method that can be used to pre-allocate the tensor.
Syntax
torch.zeros(*size,
out=None,
dtype=None,
layout=torch.strided,
device=None,
requires_grad=False)
Parameters
| Argument | Description |
| *size (int) | It defines the shape of the output tensor. For example, if the shape is 2×2, the output tensor is a 2×2 matrix of 0s. |
| out (Tensor, optional) | It is an output tensor where you can store your tensor with 0s.I |
| dtype (torch.dtype, optional) | It determines the output tensor’s data type. (e.g., torch.float32, torch.int64). The default dtype in most cases is torch.float32. |
| layout (torch.layout, optional) | It determines the memory layout of the tensor. By default, it is tensor.strided. |
| device (torch.device, optional) |
It is a device that places your output tensor. By default, it becomes your current device, but you can set it to whatever you want. (e.g., torch.device(‘cpu’), torch.device(‘cuda’) |
| requires_grad (bool, optional) |
It defines whether the tensor requires gradient computation for autograd. By default, it is False, but if True, it will enable gradient computation for autograd. |
Creating a 1D tensor filled with 0s
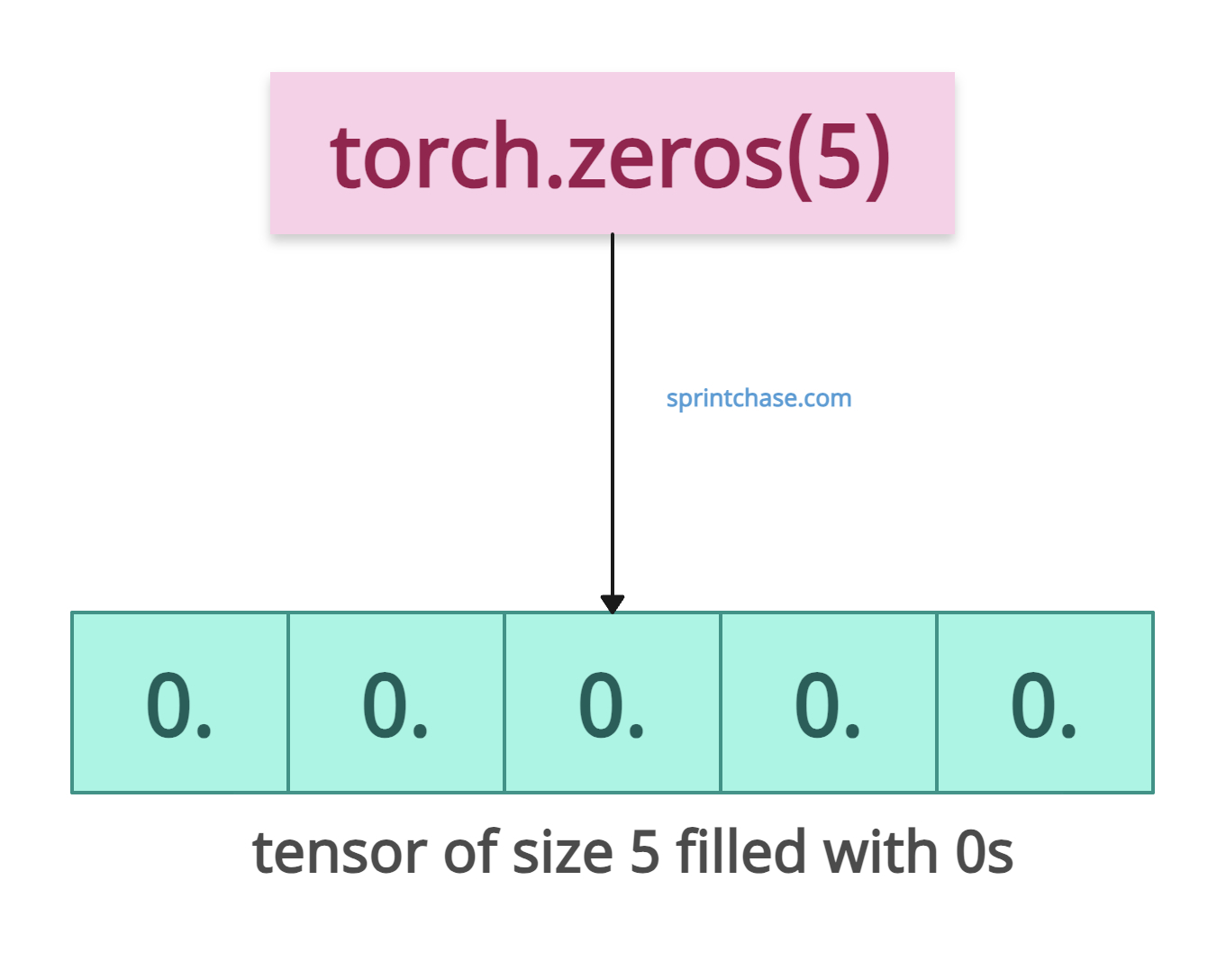
Let’s create a 1D tensor of size 5.
import torch tensor = torch.zeros(5) print(tensor) # tensor([0., 0., 0., 0., 0.])
Creating multidimensional
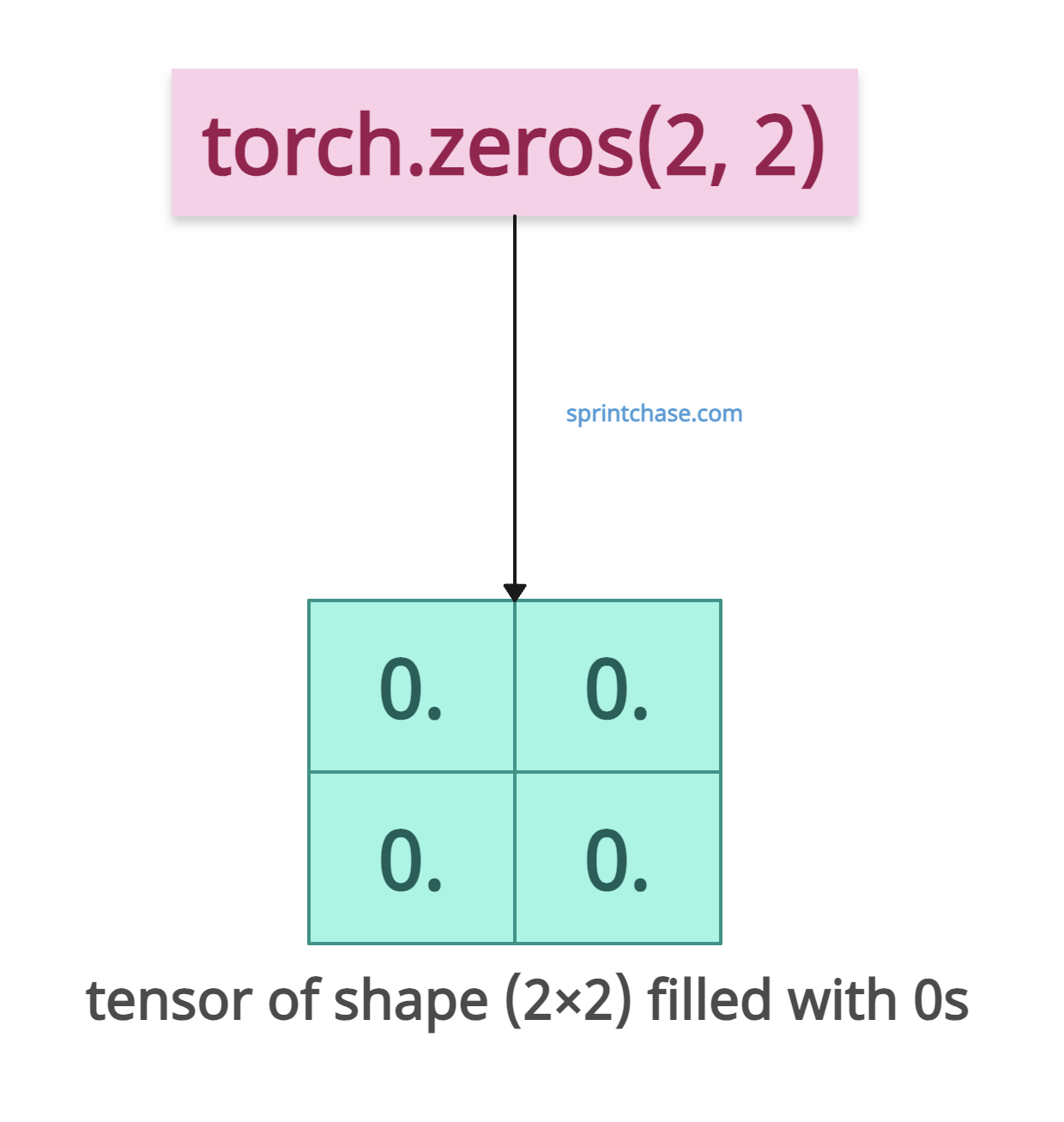 Let’s create a 2×2 tensor (matrix) filled with zero values.
Let’s create a 2×2 tensor (matrix) filled with zero values.
import torch initial_tensor = torch.zeros(2, 2) print(initial_tensor) # Output: # tensor([[0., 0.], # [0., 0.]])
If you want to see its type, you can get it using the .dtype property.
import torch initial_tensor = torch.zeros(2, 3) print(initial_tensor.dtype) # Output: torch.float32And its type is torch.float32, which is by default.
Creating a 3D tensor
import torch tensor = torch.zeros(2, 3, 4) print(tensor.shape) # Output: torch.Size([2, 3, 4])
Specifying Data Type
You can create a type of integer tensor using the “dtype=torch.int64” argument.import torch int_zeros_tensor = torch.zeros(2, 3, dtype=torch.int64) print(int_zeros_tensor) # Output: tensor([[0, 0, 0], # [0, 0, 0]]) print(int_zeros_tensor.dtype) # Output: torch.int64It can be helpful for indexing or counting tasks.
Device Placement
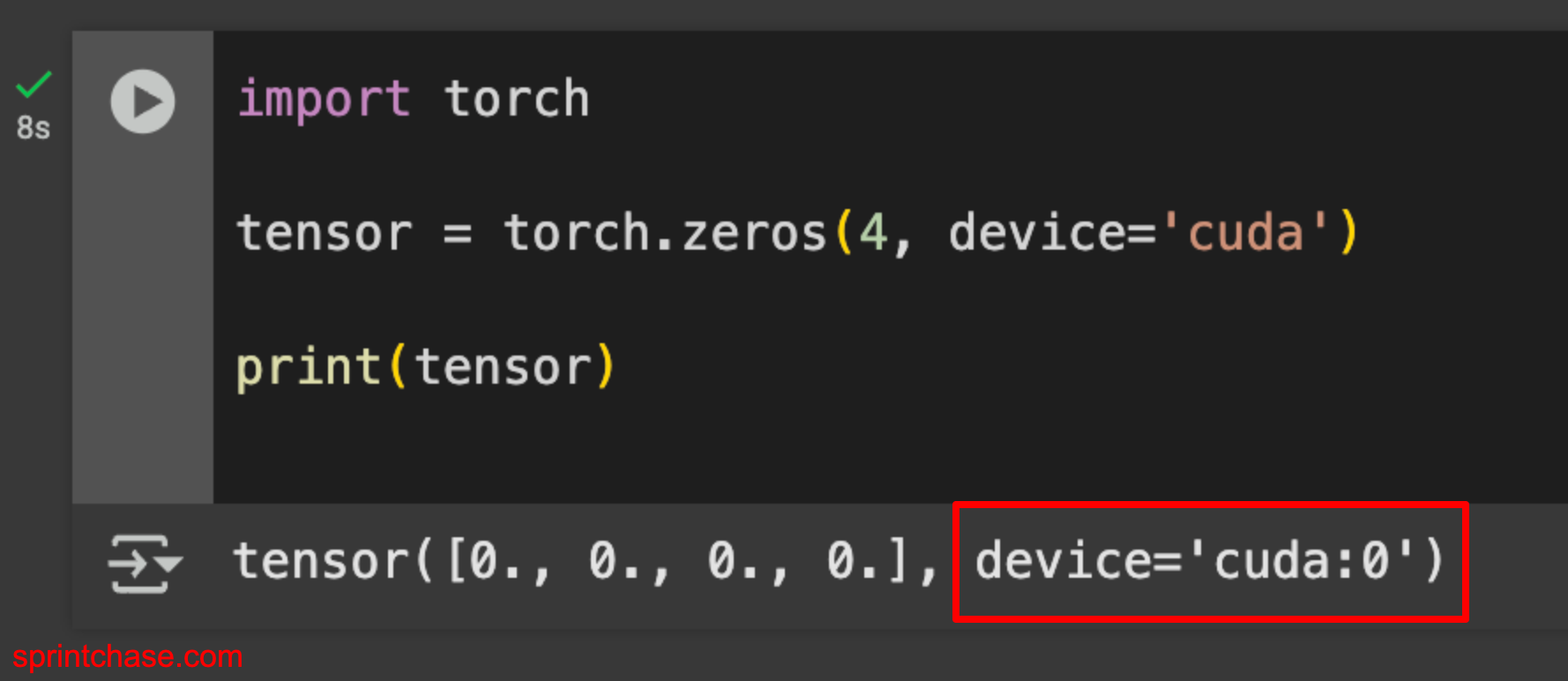
Let’s create a tensor on the GPU by passing the device=”cuda” argument.
import torch tensor = torch.zeros(4, device='cuda') print(tensor) # Output: tensor([0., 0., 0., 0.], device='cuda:0')
Autograd Integration
Let’s enable gradient tracking by passing the requires_grad=True argument.
import torch tensor = torch.zeros(3, requires_grad=True) tensor.sum().backward() print(tensor.grad) # Output: tensor([1., 1., 1.])
You can see that it enables gradient computation, where the gradient of the sum is 1 for each element.
That’s all!
