



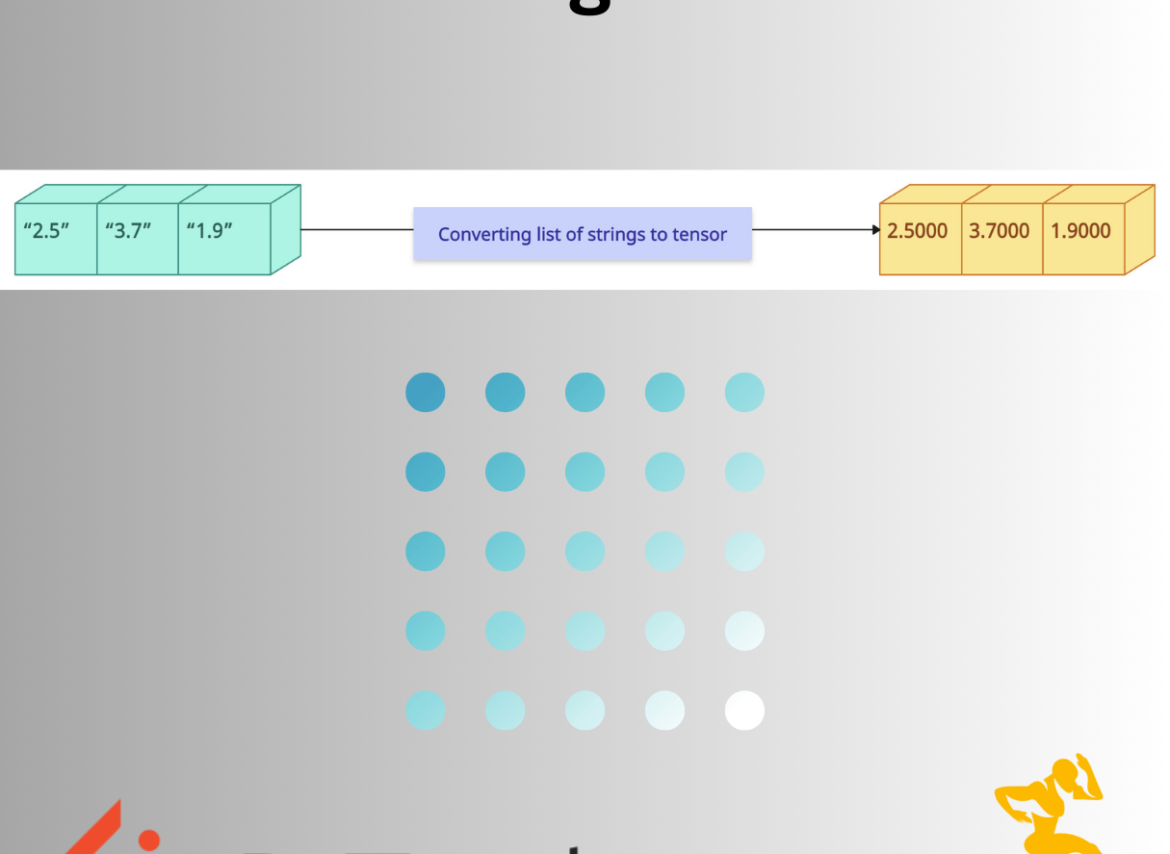
PyTorch tensors are numerical, so strings can’t be directly converted to a tensor. However, if the strings in the list represent numerical values like [“2.5”, “3.7”, “1.9”], then we can convert them into float tensors.
The above solution has one catch: the string must represent a valid numerical value; otherwise, it will throw an error, so you must implement an exception-handling mechanism.
To convert a list of strings to a tensor, you must first convert the textual data into numerical representations and then use the torch.tensor() method. This approach varies depending on the nature of the strings.

import torch
string_list = ["2.5", "3.7", "1.9"]
print(string_list)
# Output: ['2.5', '3.7', '1.9']
# For error handling (e.g., non-numeric strings):
def safe_convert(s):
try:
return float(s)
except ValueError:
return 0.0 # or handle as needed
safe_float_list = [safe_convert(s) for s in string_list]
print(safe_float_list)
# Output: [2.5, 3.7, 1.9]
tensor = torch.tensor(safe_float_list, dtype=torch.float32)
print(tensor)
# Output: tensor([2.5000, 3.7000, 1.9000])
In the above code, you carefully analyze that we initialized a list of strings representing numerical values.
We also put a try-except mechanism to handle non-numerical strings.
The final output is a list of tensors that contains float values.
Let’s pass string_list = [“a”, “b”, “c”], which is a non-numerical string, and see the output:
import torch
string_list = ["a", "b", "c"]
print(string_list)
# Output: ['a', 'b', 'c']
# For error handling (e.g., non-numeric strings):
def safe_convert(s):
try:
return float(s)
except ValueError:
return 0.0 # or handle as needed
safe_float_list = [safe_convert(s) for s in string_list]
tensor = torch.tensor(safe_float_list, dtype=torch.float32)
print(tensor)
# Output: tensor([0., 0., 0.])
We get the default output, tensor([0., 0., 0.]), which is a fallback output of exception handling.
Categorical Strings to Tensor
If you are working with categorical data (e.g., [“cat”, “dog”]), map each category to an integer.
The basic steps are these:
- Convert any type of list of categorical variables into a list of numeric variables
- Pass that list of variables to the torch.tensor() method
Manual Label Encoding
In the process of manual label encoding, we will convert a list of categorical labels (labels) into numerical values using dictionary comprehension and enumerate() function and store them as a PyTorch tensor using a torch.tensor() method.
import torch
labels = ["cat", "dog", "cat"]
unique_labels = list(set(labels))
label_to_idx = {label: idx for idx, label in enumerate(unique_labels)}
encoded = [label_to_idx[label] for label in labels]
tensor = torch.tensor(encoded, dtype=torch.long)
print(tensor)
# Output: tensor([1, 0, 1])
This tensor representation allows for efficient computation in deep learning models.
Using Scikit-Learn
The sklearn.preprocessing module provides a LabelEncoder function to help us assign unique numerical values to categorical labels. The encoded values must match the number of input labels.
For this approach, you must install the scikit-learn library. If you have not done so, type the command below:
pip install scikit-learnHere is the complete code:
import torch from sklearn.preprocessing import LabelEncoder labels = ["cat", "dog", "cat"] encoder = LabelEncoder() encoded = encoder.fit_transform(labels) tensor = torch.tensor(encoded, dtype=torch.long) print(tensor) # Output: tensor([0, 1, 0])
You can see from the above output that the output has the same length as the input list.
Text Sequences to Tensor
If your list contains sentences or words, use tokenization and padding.
import torch
from torchtext.vocab import build_vocab_from_iterator
sentences = ["hello world", "how are you"]
# Define tokenizer
def tokenizer(s):
return s.split() # Split by whitespace
# Sort the vocabulary to ensure a deterministic order
def sorted_vocab(iterator):
vocab_set = set()
for tokens in iterator:
vocab_set.update(tokens)
return sorted(vocab_set) # Sort alphabetically or by order of appearance
# Build vocabulary with sorted words
vocab = build_vocab_from_iterator([sorted_vocab(map(tokenizer, sentences))], specials=["<unk>"])
vocab.set_default_index(vocab["<unk>"]) # Set default index for unknown tokens
# Print vocabulary mapping
print("Vocabulary mapping:", vocab.get_stoi())
# Tokenize and pad sequences
tokenized = [torch.tensor(vocab.lookup_indices(tokenizer(s))) for s in sentences]
padded = torch.nn.utils.rnn.pad_sequence(tokenized, batch_first=True)
print("Padded tensor output:\n", padded)
# Output: Vocabulary mapping: {'you': 5, 'world': 4, 'hello': 2, 'how': 3, 'are': 1, '<unk>': 0}
# Padded tensor output:
# tensor([[2, 4, 0],
# [3, 1, 5]])
One-Hot Encoding
You can convert categorical strings to one-hot vectors.
import torch
# Define labels
labels = ["red", "blue", "green"]
# Create a unique mapping from labels to indices
unique_labels = list(set(labels)) # Get unique labels
label_to_idx = {label: idx for idx, label in enumerate(
unique_labels)} # Assign indices
# Convert labels to indices
indices = [label_to_idx[label] for label in labels]
# One-hot encoding tensor
one_hot = torch.zeros(len(indices), len(unique_labels))
one_hot[torch.arange(len(indices)), indices] = 1
# Printing results
print("Unique Labels:", unique_labels)
# Output: ['red', 'blue', 'green']
print("Label to Index Mapping:", label_to_idx)
# Output: {'red': 0, 'blue': 1, 'green': 2}
print("Indices:", indices)
# Output: [0, 1, 2]
print("One-Hot Encoded Tensor:\n", one_hot)
# Output:
# tensor([[1., 0., 0.],
# [0., 1., 0.],
# [0., 0., 1.]])
That’s all! 