



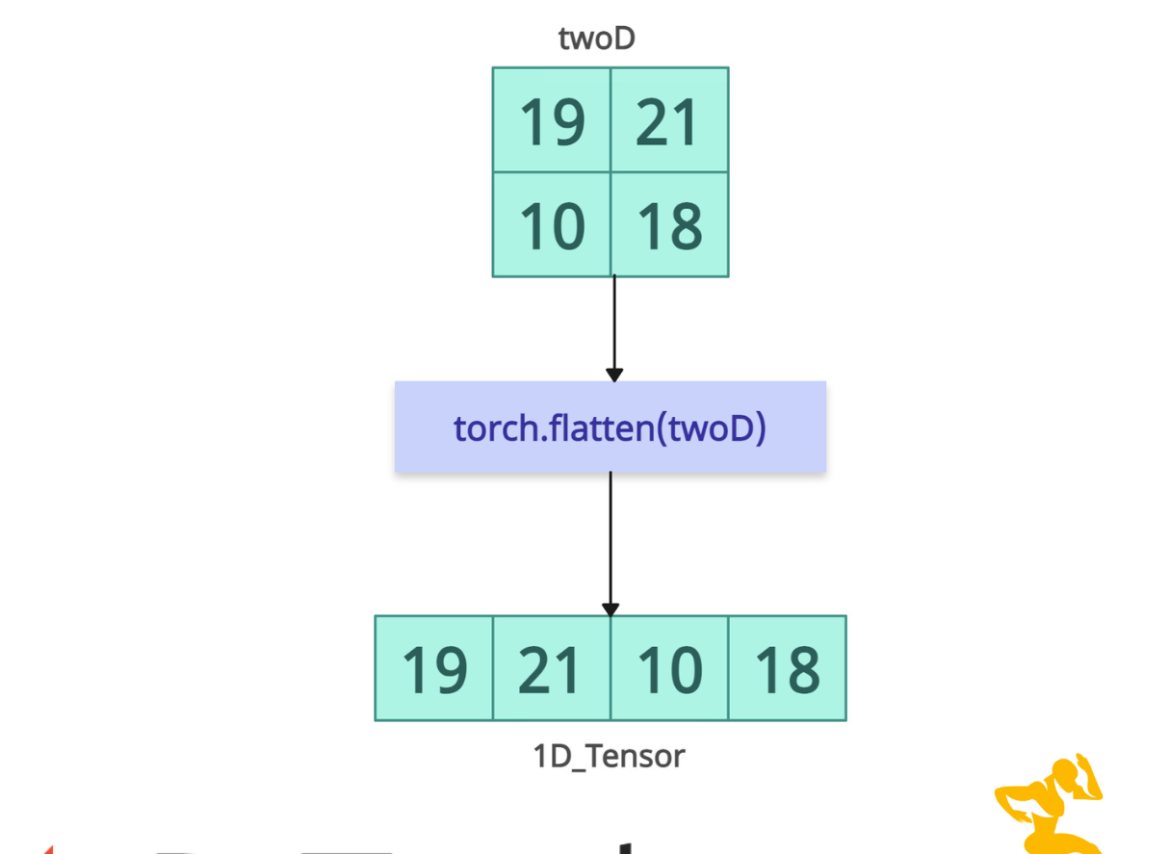
The torch.flatten() method reshapes one or more dimensional tensors into a single-dimensional tensor. It preserves the order of elements (row-major order) and returns a view whenever possible.
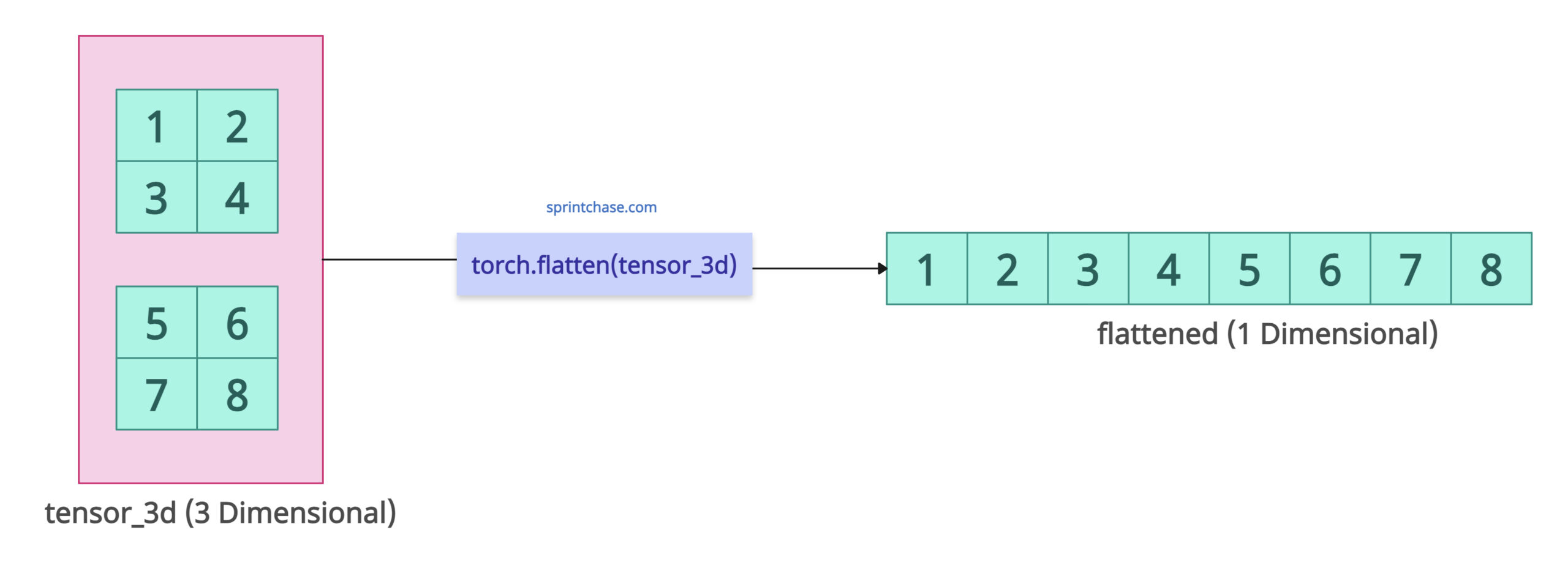
The above figure shows that if you don’t pass any specific dimension, the entire 3D tensor is flattened into 1D.
It returns the view of the original tensor; it does not change the value or copy the data. However, if an input tensor’s memory layout (e.g., non-contiguous strides) prevents a valid view, this method will copy the data to produce a contiguous tensor.
The main use case is before a Linear layer in neural networks.
The torch.flatten() is similar to tensor.view(-1) or tensor.reshape(-1) for full flattening, but flatten() is more explicit and supports partial flattening.
Syntax
torch.flatten(input, start_dim=0, end_dim=-1)
Parameters
| Argument | Description |
| input (Tensor) | It represents an input tensor that needs to be flattened. |
| start_dim (int, optional) |
It is the first dimension from which to start flattening (inclusive). By default, it is 0. |
| end_dim (int, optional) |
It is the last dimension to flatten (inclusive). Defaults to -1 (previous dimension). |
Full flattening of a Tensor
Let’s flatten a 3D tensor into a 1D tensor without passing any arguments.
import torch tensor_3d = torch.tensor([[[1, 2], [3, 4]], [[5, 6], [7, 8]]]) flattened = torch.flatten(tensor_3d) print(flattened) # Output: tensor([1, 2, 3, 4, 5, 6, 7, 8])
The above output shows it flattened from 3D to 1D.
Partial flattening of specific dimensions
You can flatten specific dimensions while preserving others by passing start_dim and end_dim arguments.
import torch tensor_3d = torch.tensor([[[1, 2], [3, 4]], [[5, 6], [7, 8]]]) flattened = torch.flatten(tensor_3d, start_dim=1, end_dim=2) print(flattened) # Output: tensor([[1, 2, 3, 4], # [5, 6, 7, 8]])
In the above code, we flattened the last two dimensions of a 3D tensor (shape [2, 2, 2]) into a single dimension, converting each 2×2 inner matrix into a 1D vector of 4 elements.
The output tensor is a 2D tensor of shape [2, 4]. It keeps the outermost dimension (dim=0).
Edge Case: Flattening a 1D Tensor

Flattening a 1D tensor returns the same tensor as input because a 1D tensor is already flattened.
import torch tensor_1d = torch.tensor([1, 11, 21, 4]) flattened_1d = torch.flatten(tensor_1d) print(flattened_1d) # Output: tensor([ 1, 11, 21, 4])
Contiguous Input (No Copy)
Since the input tensor will be contiguous, it does not require a copy.
import torch tensor_2d = torch.tensor([[1, 2], [3, 4]]) flattened_tensor = torch.flatten(tensor_2d) print(flattened_tensor) # Output: tensor([1, 2, 3, 4]) print(flattened_tensor.is_contiguous()) # Output: True
To check if a tensor is contiguous, use the .is_contiguous() method.
You can see that the flattened tensor is contiguous. So, there is no need for a copy.
What about a non-contiguous tensor?
Non-Contiguous Input (Forces Copy)
In this case, we will create a non-contiguous tensor and flatten it.
The input tensor is non-contiguous, so the .flatten() function will make a copy of the input tensor and return a contiguous flattened tensor.
import torch non_contiguous_tensor_2d = torch.tensor([[1, 2], [3, 4]]).t() print(non_contiguous_tensor_2d.is_contiguous()) # Output: False flattened_tensor = torch.flatten(non_contiguous_tensor_2d) print(flattened_tensor) # Output: tensor([1, 3, 2, 4]) print(flattened_tensor.is_contiguous()) # Output: True
In the output tensor, the values are stored in row-major order, and when the non-contiguous tensor is flattened, it is read in memory order, not visually row by row.
The flattening reads the underlying memory in the layout used by the transposed tensor, not the logical shape.
The main disadvantage of using non-contiguous tensors is that copying non-contiguous tensors can impact performance in memory-bound scenarios.
That’s it!